Классификация грибов по съедобности – Грибы Сибири
Съедобные грибы
К съедобным грибам относят виды, которые перед употреблением в пишу не требуют предварительной обработки — отваривания, вымачивания и т.п., их необходимо только очистить и можно приступать к приготовлению.
Условно-съедобные грибы
К условно-съедобным чаще всего относят грибы, ядовитые или едкого вкуса в сыром виде, но вполне съедобные после тщательной кулинарной обработки. Иногда называются и другие причины условной съедобности — например, съедобны только в молодом возрасте или вызывают отравление при совместном употреблении с определёнными продуктами (грибы-навозники с алкоголем).
Пищевое применение таких грибов основано на том, что их яды обезвреживаются при температуре выше 70°C или хорошо растворимы в горячей воде и удаляются при отваривании. Перед приготовлениям блюд из условно-съедобных грибов их необходимо отварить в большом количестве воды, отвар не используется, а отваренные грибы промывают водой.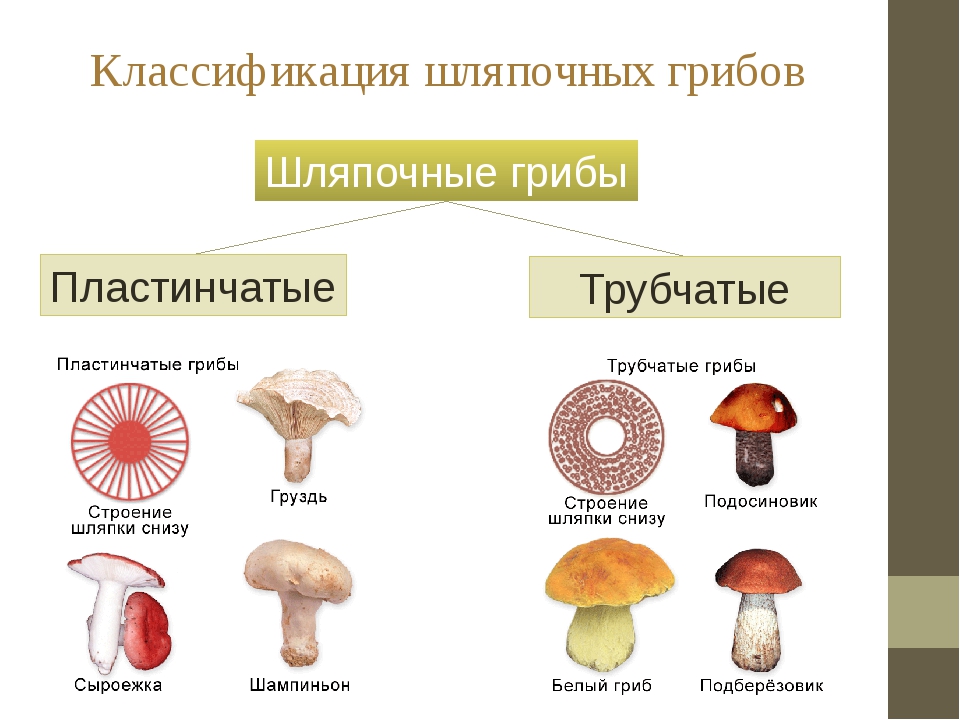
Едкие и горькие вещества из некоторых млечников удаляются тоже кипячением или вымачиванием в холодной воде в течение длительного времени.
Условно-съедобные грибы, пригодные для сушки, можно употреблять только после определённого срока хранения (обычно 2 — 3 месяца), за это время ядовитые вещества улетучиваются.
К условно-съедобным относятся некоторые грибы, считающиеся лучшими и очень вкусными — сморчки, волнушка розовая, рядовка фиолетовая, опёнок осенний.
Несъедобные грибы
Несъедобные грибы — не ядовитые грибы, по тем или иным причинам не употребляемые человеком в пищу.
Основные причины несъедобности грибов:
- Неприятный запах
- Неприятный вкус
- Малые плодовые тела
- Специфичность места произрастания
- Жёсткость мякоти
- Чешуйки, шипы, либо иные выросты на плодовом теле
Ядовитые грибы
К ядовитым грибам относятся виды, которые содержат в своём составе вещества (токсины), вызывающие нарушения жизнедеятельности организма человека, при этом данные вещества невозможно устранить с помощью предварительной обработки грибов.
Грибы для которых съедобность неизвестна
Для многих видов грибов не были проведены исследования, призванные выяснить их съедобность.
| Название | Латинское наименование | Мякоть | Произрастание | Категория |
| Белый гриб | Boletus edulis | Крепкая, сочная, мясистая, с приятным вкусом и запахом | Чаще всего в лесах с моховым или лишайниковым покровом | Первая |
| Рыжик настоящий | Lactarius deliciosus | Плотная, желто-оранжевого цвета, с позелененением на разрезе | В сосновом лесу и ельнике | |
| Груздь настоящий | Lactarius resimus | Плотная и крепкая, белого цвета, с фруктовым ароматом | В лиственных и смешанных лесных зонах | |
| Подберезовик | Leccinum | Разной плотности, с характерным грибным ароматом и вкусом | Виды образуют микоризу с березами | Вторая |
| Подосиновик | Leccinum | Разной плотности, часто волокнистая, с характерным грибным ароматом и вкусом | Виды образуют микоризу с осинами | |
| Дубовик | Boletus luridus | Желтоватого цвета, на разрезе синеющая | На известковых грунтах в лиственных и смешанных лесах | |
| Масленок | Suillus | Белая или желтоватая, на разрезе может синеть или краснеть | На лесных почвах в ельниках и под соснами | |
| Волнушка розовая | Lactarius torminosus | Белого цвета, очень крепкая, достаточно плотная, с относительно острым вкусом | Березовые рощи и смешанного типа лесные зоны | |
| Белянка | Lactarius pubescens | Плотного типа, белого цвета, ломкая, с легким ароматом | Опушка березовой рощи и редкая хвойно-березовая молодая посадка | |
| Груздь осиновый | Lactarius controversus | Плотного типа, белого цвета, ломкая, с легким фруктовым ароматом | Под ивами, осинами и тополями | |
| Шампиньон | Agaricus | Белая, может краснеть или желтеть на воздухе, с выраженным грибным ароматом | Унавоженная почва, богатый органикой лесной и луговой перегной | |
| Моховик зеленый | Xerocomus subtomentosus | Белого цвета, практически не синеет на срезе | В хвойниках и лиственных лесах | Третья |
| Валуй | Russula foetens | Достаточно хрупкая, белого цвета, на разрезе постепенно темнеющая | В хвойниках и лиственных лесах | |
| Сыроежка | Rússula | Плотного типа, хрупкая или губчатая, может изменять окрашивание | На лесных почвах, вдоль дорог | |
| Груздь черный | Lactarius necator | Достаточно плотная, ломкая, белого цвета, на срезе приобретает серое окрашивание | Смешанные лесные зоны, березняки | |
| Опенок осенний | Armillaria mellea | Плотная, беловатая, тонкая, с приятным ароматом и вкусом | Мертвая и разлагающаяся древесина, пни лиственных и еловых пород | |
| Лисичка обыкновенная | Cantharēllus cibārius | Плотно-мясистого типа, желтого окрашивания, краснеющая при надавливании | Повсеместно в лесных зонах умеренного климата | |
| Сморчок | Morchella | Пористая, с хорошим вкусом и приятным запахом | Ранние грибы, населяющие лесные зоны, парки, садовые насаждения | |
| Моховик пестрый | Xerocomellus chrysenteron | Беловатая или желтоватого цвета, интенсивно синеющая на разрезе | Хорошо разрыхленные кислые почвы лесных зон | Четвертая |
| Опенок луговой | Marasmius oreades | Тонкая, беловатого или бледно-желтого цвета, со сладковатым вкусом | Луга, пастбища, выгоны, огороды и сады, поля, обочины дорог, опушки, овраги и канавы | |
| Вешенка | Pleurotus | Белая или с незначительным желтым оттенком, приятного вкуса и запаха | Древесина в лиственных и смешанных лесах | |
| Рядовка | Tricholoma | Плотного типа, белая или немного желтоватая, не изменяющая цвет на срезе | Сухие, реже смешанного типа лесные зоны |
Классификатор грибов.

Этот классификатор создан по собственным впечатлениям автора, пытавшегося разобраться в грибах произрастающих в Южном приморье.
Используя книги и сайты посвященные грибам, я не раз натыкался на несоответствия в описании и определении пригодности для еды многих грибов попадавшихся мне в лесных походах. Многие каталоги содержат не только спорные факты о не съедобных грибах, но и ложную информацию о съедобных. Ряд таких замечаний я направил авторам ресурсов про грибы, но пока реакции не последовало.
Я не профессиональный грибник, но знание о съедобности того или иного гриба мне часто необходимо. Конечно нереально запомнить все виды , их названия и, тем более, латинскую аббревиатуру грибов Дальнего востока, но сконцентрировать внимание на том как выглядит гриб, годится он в пищу или не совсем я таки сумел.
Если вам крайне необходимы более обширные знания о грибах, воспользуйтесь электронной энциклопедией или научными трудами из библиотеки. Есть очень хорошая книга «Съедобные грибы Дальнего востока» в которой, по моему мнению, хотя и есть ряд неточностей и ошибок, но содержится обширная информация о спорах, мицелии и систематике грибного мира.
Своей целью я не ставил опровергнуть чужие теории или создать нечто новое в систематизации грибов. Здесь лишь «оперативный помощник грибника», позволяющий «на ходу» посмотреть и определить по виду — стоит брать эти грибы или нет.
Сервис разработан так, что Вам легко будет , используя сеть и телефон, пролистать картинки с грибами и , путем сравнения, определить их пригодность для еды или заготовки.
Посмотрите на гриб, подумайте какой из рисунков классификатора гриб Вам напоминает и заходите в раздел сравнения изображений с вашей находкой.
Выбрав условную категорию или используя полный каталог с картинками и фотографиями грибов, просто пролистывайте изображения до тех пор пока не увидите похожий на искомый вами гриб. Одна из надписей — вкусный, съедобный, условно-съедобный, не съедобный, ядовитый подскажет вам — стоит брать этот гриб или нет.
Кроме этого на сайте содержится более подробная информация о вкусовых качествах, способах приготовления и заготовки собранных вами грибов. Самые знаменитые рецепты блюд с грибами, редкие кушанья и соленья. Полезные хотя и не съедобные грибы описаны в виде рецептов народной медицины, а не стандартные способы применения ядовитых и галлюциногенных грибов описаны в закрытом разделе попасть в который суждено не каждому — на входе в раздел придется пройти небольшой тест на адекватность восприятия информации.
Самые знаменитые рецепты блюд с грибами, редкие кушанья и соленья. Полезные хотя и не съедобные грибы описаны в виде рецептов народной медицины, а не стандартные способы применения ядовитых и галлюциногенных грибов описаны в закрытом разделе попасть в который суждено не каждому — на входе в раздел придется пройти небольшой тест на адекватность восприятия информации.
Я люблю собирать, готовить и есть грибы, угощать друзей и рассказывать байки о грибниках и лесных странствиях.
Желаю Вам удачной «тихой охоты» и приятного аппетита!
Создание идеального грибного классификатора
Дата публикации Jan 2, 2019
фотоФлориан ван ДуйннаUnsplashНа пицце или в ризотто грибы просто великолепны на вкус! Но с более чем 10 000 видов грибов только в Северной Америке, как мы можем определить, какие из них съедобны?
Это цель этого проекта. Мы создадим классификатор, который определит, является ли определенный гриб съедобным или ядовитым. Для этого мы будем использоватьлогистическая регрессия,линейный дискриминантный анализ(LDA) иквадратичный дискриминантный анализ(QDA). Многое будет рассмотрено в этой статье:
Для этого мы будем использоватьлогистическая регрессия,линейный дискриминантный анализ(LDA) иквадратичный дискриминантный анализ(QDA). Многое будет рассмотрено в этой статье:
- Как использоватьпандзагружать и манипулировать данными
- Как построить категориальные данные срожденное море
- Как использоватьscikit учитьсяпостроить наш классификатор с логистической регрессией, LDA и QDA
- Как разделить наш набор данных на наборы поездов / тестов
- Как построить кривую ROC для оценки качества классификатора
Конечно, все будет сделано в Python.полная тетрадьинабор данныхдоступны.
Запустите свой ноутбук Jupyter и начните!
набор данныхмы будем использовать содержит 8124 экземпляров грибов с 22 функциями. Среди них мы находим форму крышки гриба, цвет крышки, цвет жабры, тип вуали и т. Д. Конечно, это также говорит нам, является ли гриб съедобным или ядовитым.
Давайте импортируем некоторые библиотеки, которые помогут нам импортировать данные и манипулировать ими.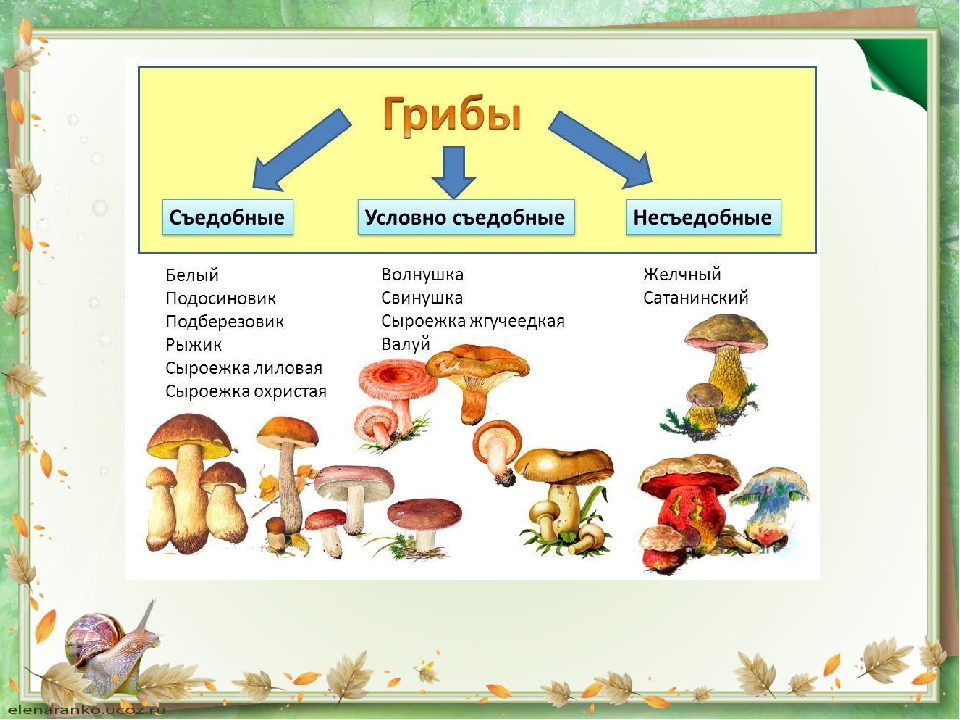 В вашей записной книжке запустите следующий код:
В вашей записной книжке запустите следующий код:
Исследовательский анализ данных
Общий первый шаг для проекта науки о данных состоит в том, чтобы выполнитьисследовательский анализ данных(ЭДА). Этот шаг обычно включает в себя изучение дополнительных данных, с которыми вы работаете. Возможно, вы захотите узнатьформавашего набора данных (сколько строк и столбцов), количество пустых значений и визуализировать части данных, чтобы лучше понять взаимосвязь между функциями и целью.
Импортируйте данные и увидите первые пять столбцов со следующим кодом:
Всегда хорошо иметь набор данных вданныепапка в каталоге проекта. Кроме того, мы сохраняем путь к файлу в переменной, так что, если путь когда-либо изменяется, нам нужно только изменить присвоение переменной.
После запуска этой ячейки кода вы должны увидеть первые пять строк. Вы замечаете, что каждая функция является категориальной, и для определения определенного значения используется буква. Конечно, классификатор не может принимать буквы в качестве входных данных, поэтому нам придется изменить это в конце концов.
Конечно, классификатор не может принимать буквы в качестве входных данных, поэтому нам придется изменить это в конце концов.
Пока давайте посмотрим, если наш набор данныхнесбалансированный.Несбалансированный набор данных — это когдаодин класс гораздо больше, чем другой, В идеале, в контексте классификации, мы хотим равное количество экземпляров каждого класса. В противном случае нам нужно будет реализовать расширенные методы выборки, такие какпередискретизация меньшинства.
В нашем случае мы хотим посмотреть, есть ли в наборе данных равное количество ядовитых и съедобных грибов. Мы можем построить частоту каждого класса следующим образом:
И вы получите следующий график:
Подсчет каждого классаПотрясающе! Это похоже на довольно сбалансированный набор данных с почти равным количеством ядовитых и съедобных грибов.
Теперь я хотел посмотреть, как каждая функция влияет на цель. Для этого я сделал гистограмму всех возможных значений, разделенных классом грибов. Делать это вручную для всех 22 функций не имеет смысла, поэтому мы создаем эту вспомогательную функцию:
Делать это вручную для всех 22 функций не имеет смысла, поэтому мы создаем эту вспомогательную функцию:
оттенокдаст цветовой код ядовитому и съедобному классу.данныеПараметр будет содержать все функции, кроме класса гриба. Выполнение кода ячейки ниже:
Вы должны получить список из 22 участков. Вот пример вывода:
Поверхность крышкиПотратьте некоторое время на просмотр всех графиков.
Теперь посмотрим, есть ли у нас пропущенные значения. Запустите этот кусок кода:
И вы должны увидеть каждый столбец с количеством пропущенных значений. К счастью, у нас есть набор данных без пропущенных значений. Это очень редко, но мы не будем жаловаться.
Готовимся к моделированию
Теперь, когда мы знакомы с данными, пришло время подготовить их к моделированию. Как упоминалось ранее, объекты имеют буквы, представляющие различные возможные значения, но нам нужно превратить их в числа.
Для этого мы будем использоватькодирование этикеткиа такжегорячая кодировка
Давайте сначала используем кодирование метки в целевом столбце. Запустите следующий код:
Запустите следующий код:
И теперь вы заметили, что столбец теперь содержит 1 и 0.
Результат метки, кодирующей столбец «класс»Теперь ядовитое обозначено 1, а съедобное — 0. Теперь мы можем считать наш классификатор «ядовитым или нет». Ядовитый гриб получает 1 (true), а съедобный гриб — 0 (false).
Следовательно,кодирование этикеткипревратит категорический признак в числовой. Однако не рекомендуется использовать кодирование меток, когда существует более двух возможных значений.
Зачем?
Потому что тогда он присвоит каждому значению 0, 1 или 2 Это проблема, потому что «2» можно рассматривать какболее важныйи из этого можно извлечь ложные корреляции.
Чтобы избежать этой проблемы, мы используемгорячее кодированиена других особенностях. Чтобы понять, что он делает, давайте рассмотрим форму крышки первой точки входа. Вы видите, что оно имеет значение «х», которое обозначает выпуклую форму колпачка. Однако в наборе данных записано всего шесть разных форм колпачков. Если мы одноразово закодируем функцию, мы должны получить:
Однако в наборе данных записано всего шесть разных форм колпачков. Если мы одноразово закодируем функцию, мы должны получить:
Как видите, форма шапки теперь является векторной. 1 обозначает фактическое значение формы шапки для записи в наборе данных, а остальное заполнено 0. Опять же, вы можете думать о 1 какправдаи 0 какложный.
Недостаток однократного кодирования состоит в том, что он вводит больше столбцов в набор данных. В случае формы колпачка мы переходим от одного столбца к шести столбцам. Для очень больших наборов данных это может быть проблемой, но в нашем случае дополнительные столбцы должны быть управляемыми.
Давайте продолжим и быстро закодируем остальные функции:
И теперь вы должны увидеть:
Набор горячих закодированных данныхВы заметили, что мы поднялись с 23 столбцов до 118. Это пятикратное увеличение, но их недостаточно, чтобы вызвать проблемы с памятью компьютера.
Теперь, когда наш набор данных содержит только числовые данные, мы готовы начать моделирование и делать прогнозы!
Поезд / тестовый сплит
Прежде чем углубляться в моделирование и делать прогнозы, нам нужно разделить наш набор данных на обучающий набор и набор тестов. Таким образом, мы можем обучить алгоритм на тренировочном наборе и делать прогнозы на тестовом наборе. Метрики ошибок будут намного более релевантными, так как алгоритм будет делать прогнозы для данных, которых он не видел раньше.
Мы можем легко разделить набор данных следующим образом:
Вот,Yпросто цель (ядовитая или съедобная). Затем,Иксэто просто все особенности набора данных. Наконец, мы используемtrain_test_splitфункция.test_sizeПараметр соответствует части набора данных, которая будет использоваться для тестирования. Обычно мы используем 20%. Тогдаrandom_stateПараметр используется для воспроизводимости. Он может быть установлен на любое число, но он гарантирует, что при каждом запуске кода набор данных будет разделен одинаково.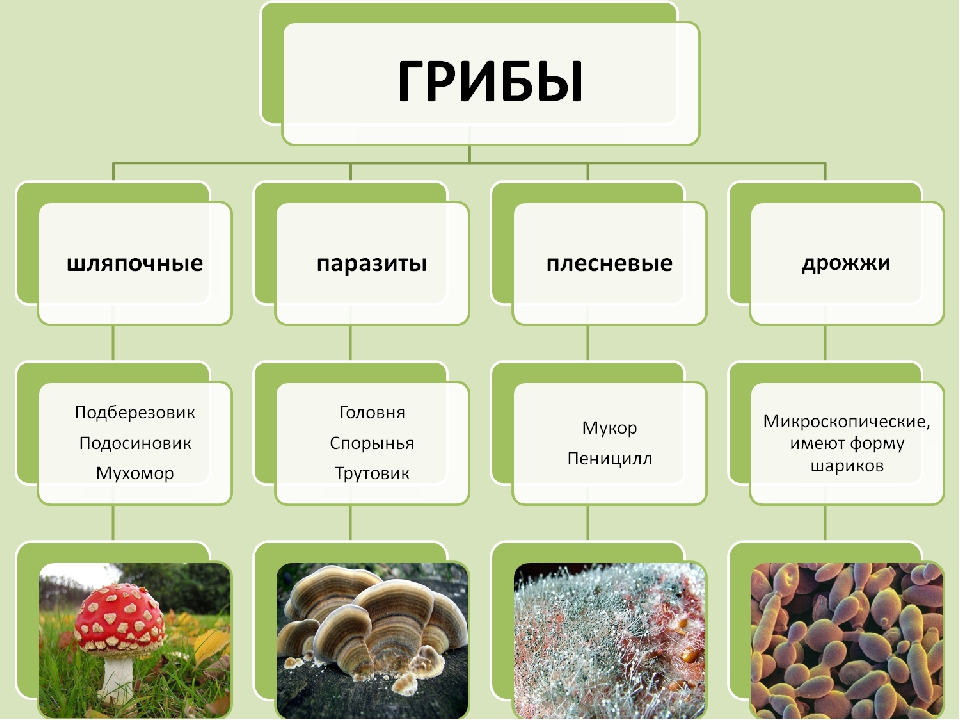 Если нетrandom_stateпри условии, что поезд и набор тестов будут различаться, так как функция разбивает их случайным образом.
Если нетrandom_stateпри условии, что поезд и набор тестов будут различаться, так как функция разбивает их случайным образом.
Хорошо, мы официально готовы начать моделирование и делать прогнозы!
Логистическая регрессия
Сначала мы будем использовать логистическую регрессию. На следующих этапах мы будем использовать область под кривой ROC и матрицу путаницы в качестве метрик ошибок. Они обычно используются для оценки эффективности классификаторов, как обсуждалосьВот,
Давайте сначала импортируем все, что нам нужно:
Затем мы делаем примерЛогистическая регрессияОбъект и пример модели для учебного набора:
Затем мы предсказываем вероятность того, что гриб ядовит. Помните, мы относимся к грибам как к ядовитым или неядовитым.
Кроме того, вы должны напомнить, чтологистическая регрессиявозвращает вероятность. А пока давайте установим порог на 0,5. Таким образом, если вероятность больше 0,5, гриб будет классифицирован как ядовитый. Конечно, если вероятность меньше порога, гриб классифицируется как съедобный.
Конечно, если вероятность меньше порога, гриб классифицируется как съедобный.
Это именно то, что происходит в ячейке кода ниже:
Обратите внимание, что мы рассчитали вероятности на тестовом наборе.
Теперь давайте посмотримМатрица путаницы.Это покажет нам истинно положительные, истинно отрицательные, ложноположительные и ложноотрицательные показатели.
Пример путаницыМы выводим нашу матрицу путаницы следующим образом:
И вы должны получить:
Путаница матрицаУдивительно! Наш классификатор идеален! Из приведенной выше матрицы путаницы вы видите, что наши ложноположительные и ложноотрицательные показатели равны 0, что означает, что все грибы были правильно классифицированы как ядовитые или съедобные!
Давайте напечатаем область под кривой ROC. Как известно, для идеального классификатора он должен быть равен 1.
Действительно, кодовый блок выше выводит 1! Мы можем сделать нашу собственную функцию для визуализации кривой ROC:
И вы должны увидеть:
Кривая ROCПоздравляем! Вы создали идеальный классификатор с базовой моделью логистической регрессии.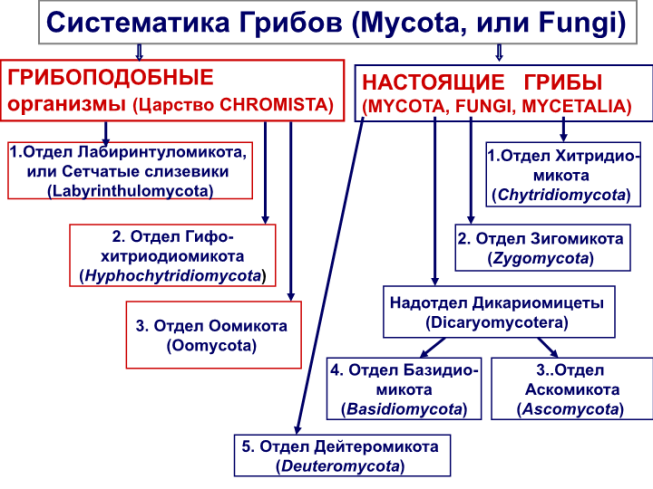
Тем не менее, чтобы получить больше опыта, давайте создадим классификатор, используя LDA и QDA, и посмотрим, получим ли мы аналогичные результаты.
Классификатор с LDA
Следуя тем же шагам, изложенным для логистической регрессии:
Если вы запустите приведенный выше код, вы увидите, что мы снова получаем идеальный классификатор, результаты которого идентичны классификатору, использующему логистическую регрессию.
Классификатор с QDA
Теперь мы повторяем процесс, но используяQDA:
И снова результаты одинаковы!
Как видите, мы создали идеальный классификатор для грибов с простой моделью логистической регрессии. Затем мы воспроизвели те же результаты, используя LDA и QDA.
Вы также изучили базовый рабочий процесс ученого по данным и научились использоватьрожденное моредля визуализации, и как адекватно сравнить ваши модели, разделив ваши данные на обучающие и тестовые наборы.
Я надеюсь, что вы просмотрели этот пост с блокнотом Jupyter и вам удалось воспроизвести результаты.
Если у вас есть какие-либо вопросы, дайте мне знать в комментариях. Кроме того, дайте мне знать, если вы предпочитаете иметь код в блоке кода или в виде изображения. Картинки более привлекательны, но блоки кода могут быть более практичными.
Наконец, это действительно побуждает меня продолжать, если вы можете дать несколько хлопков в этой статье. Кроме того, следите за обновлениями еще больше проектов и концепций науки о данных!
Счастливого обучения!
Оригинальная статья
Пищевая ценность культивируемых грибов и их роль в питании населения РФ
- Главная
- Новости
- Пищевая ценность культивируемых грибов и их роль в питании населения РФ
Лесные грибы на территории РФ используются в пищу с давних пор. Их популярности способствовало принятие Древней Русью православия, которое предусматривало большое количество постов, для соблюдения которых около 200 дней в году ограничивалось потребление животного белка.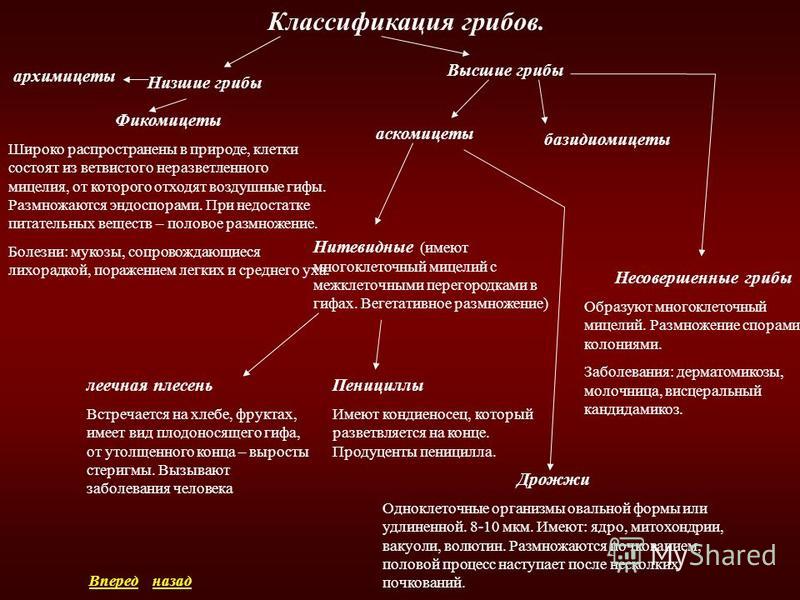 Грибы в это время были одним из немногих источников белка и использовались в пищу в большом количестве. В И.Е. Забелин в «Истории города Москвы» писал «в 17 веке на патриаршем столе в постные дни преобладала разнородная растительная пища, и по преимуществу грибы». В постный день на праздник Воздвижения Честного Креста Господня Святейшему было подано столового кушанья 19 блюд. Из них 7 блюд были с грибами.
Грибы в это время были одним из немногих источников белка и использовались в пищу в большом количестве. В И.Е. Забелин в «Истории города Москвы» писал «в 17 веке на патриаршем столе в постные дни преобладала разнородная растительная пища, и по преимуществу грибы». В постный день на праздник Воздвижения Честного Креста Господня Святейшему было подано столового кушанья 19 блюд. Из них 7 блюд были с грибами.
Традиции потребления лесных грибов продолжали существовать в СССР и поддерживались их доступностью и бесплатностью. По различным оценкам в советское время население СССР потребляло от 6 до 8 кг лесных грибов на человека в год. В это время велась заготовка лесных грибов и был сформирован классификатор съедобных грибов, где они делились на четыре категории вкусовой и пищевой ценности. По этой классификации самыми вкусными и питательными считались белый гриб, рыжик и груздь настоящий. Они относились к грибам первой категории.
Шампиньоны относились ко второй категории. Вместе с подосиновиками, подберезовиками, волнушками, осиновым и желтым груздями и подгрузком белым.
На основании каких характеристик проводилось это деление — не очень понятно. Шампиньонов у нас выращивалось мало и их свойства мало кто изучал. Вероятно, имелся в виду шампиньон полевой (односпоровый).
В отличие от России в большинстве стран мира население употребляет в пищу в основном культивируемые грибы. В Европе, Северной Америке и Австралии грибом № 1 по объемам потребления является культивируемый шампиньон. Уровень потребления находится на уровне 2,5 – 3,5 кг на душу населения в год. Питательные и полезные свойства шампиньонов изучают в университетах и исследовательских центрах. Они указываются на упаковках грибов. О них регулярно пишется в научных и научно-популярных изданиях.
- Общепринятые в западном мире характеристики шампиньона как продукта питания.
В 100 гр свежих шампиньонов содержится:
0 гр холестирина
0-0,3 гр жира
3,3 гр белка
0,3 гр углеводов
Соотношение белки – жиры 10:1
Каллорийность — 24 ккал
Таким образом шампиньоны общепризнаны низкокалорийным продуктом с высоким содержанием белка и практически отсутствием жиров.
- Витамины и минералы
Кроме того, шампиньоны называются «Суперфуд» – суперпродуктом!
Причиной этого является то, что:
В 100 гр шампиньонов (РСНП — рекомендуемая суточная норма потребления):
8-22 мкргр (11-31% РСНП) Селена
98-376 мгр (3-11% РСНП) Калия – больше чем в томатах, цукини и огурцах
0,45 мгр (15% РСНП) Меди – больше чем в авокадо и зеленом горошке
0.9-3 мгр (9-30% РСНП) Витамина В5 Пантотеновая кислота – больше чем в авокадо, брокколи и кукурузе
0.1-0,4 мгр (10-20% РСНП) Витамина В2 Рибофлавина — больше чем в петрушке и брокколи.
1,3-5,9 мгр (7-30% РСНП) Витамина В3 Ниацина – больше чем в зеленом горошке, авокадо и петрушке
Устойчивость к термообработке
Современные технологии выращивания овощей и фруктов предусматривают применение пестицидов и гербицидов, что влияет на снижение в них реального содержания полезных веществ. При выращивании шампиньонов гербициды и пестициды запрещены.
- Клетчатка и хитин
В 100 граммах сырых шампиньонов содержится 1,5 гр клетчатки (5-6% РСПН), а в приготовленных с выпариванием воды -2,7 гр. (9-11% РСПН)
Грибная клетчатка нерастворима. В отличие от растений, где стенки клеток состоят из целлюлозы, грибная клетчатка имеет в составе своих клеток хитин и глюкан. Поэтому свойства грибной клетчатки отличаются от растительной.
Хитин, попадая в организм связывает пищевые липиды:
- уменьшает активность всасывания жиров в кишечнике.
- Поддерживает здоровый уровень холестерина в крови.
15% грибной клетчатки – это устойчивые крахмалы типа 1, который могут действовать как пребиотик, становясь пищей для полезных бактерий толстой кишки.
Научные исследования показывают, что это — весьма полезно для организма:
- усиливает кровоток в области толстой и прямой кишки,
- улучшает циркуляцию нутриентов,
- снижает рост патогенных бактерий,
- снижает всасываемость токсичных / канцерогенных веществ,
- помогает организму получать больше минералов,
- снижает риск появления рака прямой кишки.


Исследования Университета Западного Сиднея показали, что употребление мышами в пищу шампиньонов снижало у них уровень холестерина и глюкозы в крови, в тоже время повышал уровень HDL холестерина.
- Антиоксиданты
По опубликованным результатам различных исследований шампиньоны находятся в пятерке овощей с самыми высоким антиоксидантными свойствами.
В 100 гр свежих шампиньонов содержится 2,8- 4,9 мг натурального антиоксиданта Эрготионина.
Человеческое тело не содержит и не производит эрготионин. Шампиньоны являются самым богатым его источником вместе с мясом, овсяными отрубями, ростками пшеницы, некоторыми бобовыми и луком. В других овощах и фруктах эрготионин отсутствует.
Исследования показали, что в процессе термической обработки уровень эрготионина не уменьшается.
- Противораковые свойства
Исследования, проводившиеся Университетом Западного Сиднея в Корее показали, что ежедневное употребление в пищу женщинами 10 и более грамм шампиньонов на 60% снижало риск заболевания раком груди
Западная, а также юго-восточная диетология рекомендует регулярное употребление культивируемых грибов с разовой порцией 100-150 гр.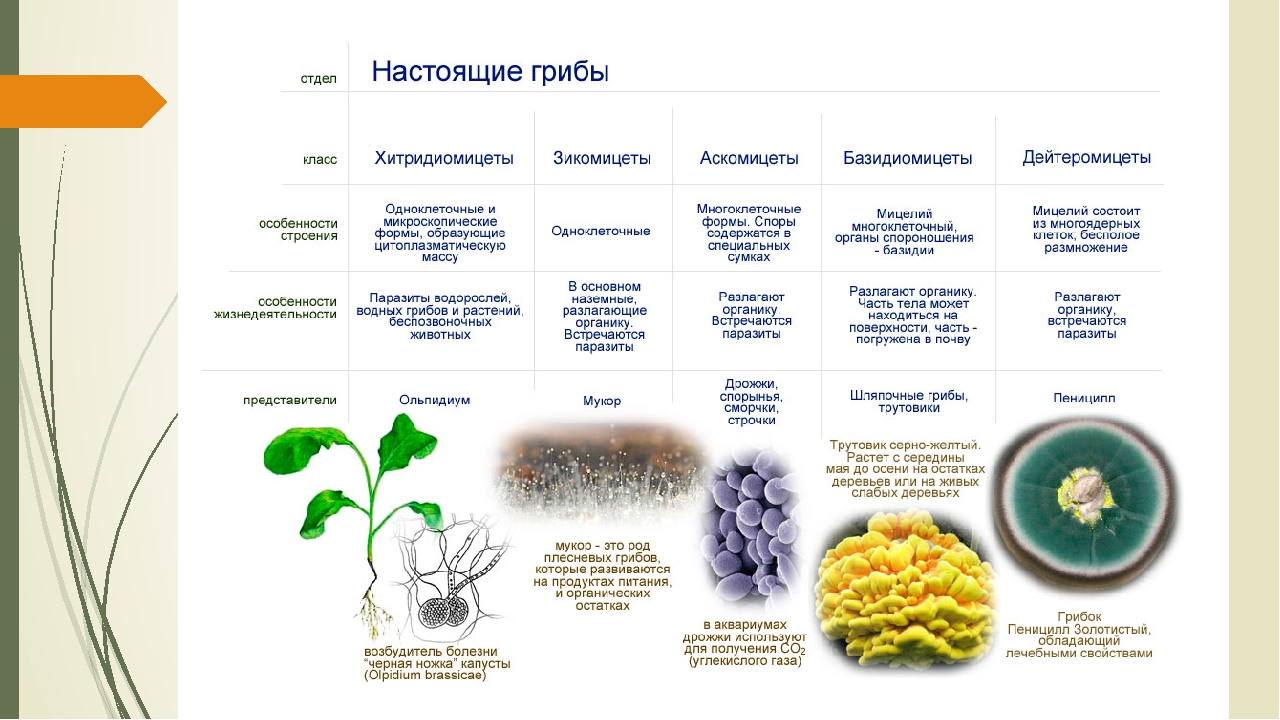 При такой порции шампиньоны обеспечат:
При такой порции шампиньоны обеспечат:
- около 5% суточной потребности человека в белке;
- 20% РСНП селениума
- 15% РСНП меди
- 8% РСНП калия,
- Не менее 20% РСНП витаминов В2, В3, В5
- Снижает риск заболевания рака груди у женщин и рака простаты у мужчин
- Поддерживает здоровый уровень холестерина в крови
Российская грибная индустрия надеется на более внимательное отношение отечественных диетологов и нутрициологов к культивируемым грибам и объективную оценку их питательных и полезных свойств.
Источник: Школа Грибоводства, октябрь 2018 г
Рассказать друзьям
| 01.12 | Овощеводство; декоративное садоводство и производство продукции питомников |
01. |
Овощеводство |
| 01.12.02 | Декоративное садоводство и производство продукции питомников |
| 01.12.03 | Выращивание грибов, сбор лесных грибов и трюфелей |
| 01.12.1 | Овощеводство |
01. 12.2 12.2 |
Декоративное садоводство и производство продукции питомников |
| 01.12.3 | Выращивание грибов, сбор лесных грибов и трюфелей |
| 01.12.31 | Выращивание грибов и грибницы (мицелия) |
| 01.12.32 | Сбор лесных грибов и трюфелей |
01. 12.35 12.35 |
Строительство спортивных и туристских (прогулочных) судов |
| 01.12.51 | Деятельность агентов по оптовой торговле топливом |
| 01.12.63 | Хранение и складирование замороженных или охлажденных грузов |
| 01.12.67 | Брокерская деятельность |
01. 12.70 12.70 |
Покупка и продажа собственного жилого недвижимого имущества |
| 01.12.74 | Деятельность в области бухгалтерского учета |
Классификация микроскопических грибов
Плесневые грибы разделяют на пять классов в основном по особенностям размножения.
1. Класс Архимицетес (архимицетовые). Наиболее примитивные грибы, у которых вообще нет мицелия или он слаборазвит. Бесполое размножение осуществляется подвижными зооспорами.
Большинство архимицетов — внутриклеточные паразиты растений. В пораженных органах растения образуются покоящиеся споры с толстыми оболочками (цисты). Примером может служить гриб, вызывающий заболевание капусты «черная ножка».
Примером может служить гриб, вызывающий заболевание капусты «черная ножка».
Паразит поселяется в корневой шейке рассады и приводит к ее отмиранию.
Другой гриб вызывает рак картофеля. Споры его перезимовывают в почве, весной прорастают в подвижные зооспоры, которые заражают молодые растения.
2. Класс Фикомицетес (фикомицетовые). Сюда входят плесневые грибы с хорошо развитым мицелием, почти у всех несептированным. Размножаются половым или вегетативным способом. Споры (в первом случае — зооспоры или зигоспоры, во втором — подвижные зооспоры с двумя жгутиками) образуются в спорангиях. К классу фикомицетов относятся широко распространенные в природе грибы рода Мукор, обитающие в почве и на различных пищевых продуктах. Размножаются они с помощью спор, образующихся в спорангиях на особых гифах — спорангиеносцах — различной формы.
Для рода Мукор характерны одиночные простые и ветвящиеся спорангиеносцы (рис. 8). Многие мукоровые грибы вызывают спиртовое или окислительное брожение, и их применяют для производства органических кислот и спирта. Некоторые мукоровые грибы являются паразитами животных и растений.
Некоторые мукоровые грибы являются паразитами животных и растений.
Рис. 8. Головчатая плесень рода Мукор: а — спорангии со спорами; б — споры; в — мицелий.
3. Класс Аскомицетес (аскомицетовые, или сумчатые грибы). Различные по строению и свойствам плесневые грибы, имеющие одноклеточный или многоклеточный мицелий. Бесполое размножение осуществляется конидиями, половое — спорами в сумках (аскоспоры).
Представителями мицелиальных сумчатых грибов являются грибы рода Эндомицес, мицелий которых часто распадается на отдельные клетки. Клетки размножаются почкованием. К сумчатым грибам, не образующим мицелия, принадлежат дрожжи.
Среди аскомицетов встречаются паразиты культурных растений, возбудители порчи пищевых продуктов, а также грибы, используемые в промышленности. К аскомицетам относятся широко распространенные плесневые грибы родов Аспергиллус и Пенициллиум, размножающиеся конидиями.
Аспергиллус (булавовидная плесень) часто встречается на поврежденном зерне, в хмеле, в сырых помещениях, на сырой таре и на остатках сахаросодержащих жидкостей.
Молодые конидии имеют светло-зеленую окраску, затем темнеют и становятся серо-бурыми. Конидиеносцы прямые с шаровидными вздутиями на концах. На вздутиях радиально вырастают клетки — стеригмы, по форме напоминающие бутылки (рис. 9, а). Из стеригм в большом количестве развиваются и отшнуровываются конидии. Иногда они совершенно закрывают вздутие конидиеносца.
Рис. 9. Сумчатые грибы (аскомицеты): а — Аспергиллус: 1 — конидии; 2 — мицелий с конидиеносцами разного возраста; 3 — конидиеносец; 4 — раздвоенные стеригмы; б — Пенициллиум: 1 — конидии; 2 — прорастающие конидии и развитие мицелия; 3 — развитие конидиеносца; 4 — различные конидиеносцы с конидиями.
Пенициллиум (рис. 9, б) — зеленая кистевидная плесень. Для всех видов рода Пенициллиум общим признаком является окраска, которая вначале развития бывает белой, затем серо-зеленой и наконец серо-бурой.
Многоклеточные конидиеносцы плесени Пенициллиум имеют вид кисти и оканчиваются разветвленными стеригмами.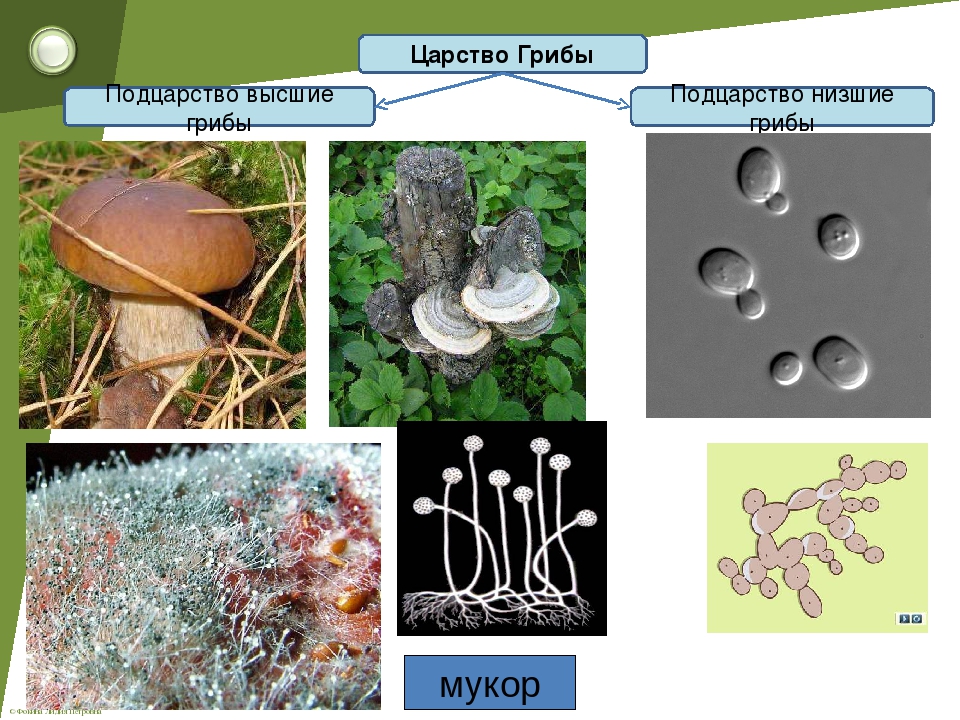 На концах их, как четки, расположены конидии. По мере созревания конидии осыпаются, образуя на окружающих предметах сизую пыль. Эта плесень распространена повсеместно и при наличии влаги появляется на всех пищевых продуктах. Конидии грибов Пенициллиум постоянно находятся в воздухе, на плодах, зерне (особенно на раздавленных зернах), солоде и др.
На концах их, как четки, расположены конидии. По мере созревания конидии осыпаются, образуя на окружающих предметах сизую пыль. Эта плесень распространена повсеместно и при наличии влаги появляется на всех пищевых продуктах. Конидии грибов Пенициллиум постоянно находятся в воздухе, на плодах, зерне (особенно на раздавленных зернах), солоде и др.
Отдельные виды применяют для получения лечебного препарата — антибиотика пенициллин.
4. Класс Базидиомицетес (базидиомицетовые, или базидиальные грибы). Грибы с ветвистым септированным мицелием. Размножаются половым и вегетативным способом. Органы размножения — базидии со спорами. Базидии бывают разного строения: одно- и многоклеточные. К первой группе относятся шляпочные грибы и трутовики, разрушающие древесину, ко второй — в основном паразитические грибы, поражающие растения. Головневые грибы поражают зерновые культуры, вызывая болезнь, называемую головней. Ржавчинные грибы поражают различные культурные растения.
5. Класс грибов несовершенных. Многоклеточные грибы, которые размножаются только конидиями (бесполое размножение). Широко распространены в природе, многие вызывают плесневение пищевых продуктов. Некоторые несовершенные грибы являются паразитами культурных растений. Так, грибы рода Фузариум вызывают заболевания овощей и плодов. Зерно, перезимовавшее в поле и пораженное грибом, при употреблении вызывает пищевое отравление.
Некоторые виды фузариумов вызывают порчу картофеля (болезнь «сухая гниль»). Гриб Ботритис вызывает порчу лука, капусты, моркови, томатов, заболевания ягод. Альтернария поражает корнеплоды в период хранения (болезнь «черная гниль»). Гриб Оидиум портит квашеные овощи и кисломолочные продукты, прессованные дрожжи, образуя на поверхности белую бархатистую пленку. Некоторые фузариумы вызывают также сердцевинную гниль свеклы. На пищевых продуктах (масле, сыре, мясе, яйцах) появляются черные пятна, что приводит к их порче.
CallumHoughton18 / Классификация грибов: использование машинного обучения для прогнозирования съедобности гриба.

Проект, прототип которого был создан в Octave и реализован на Python, для использования машинного обучения для классификации грибов как ядовитых / съедобных с использованием набора данных о грибах из репозитория машинного обучения UCI, который можно просмотреть здесь.
Модель обучается с использованием комбинации логистической регрессии и градиентного спуска в качестве метода минимизации.
Идея заключалась в том, чтобы представить эту модель с помощью минималистичного RESTful API, но с акцентом на передовые методы разработки API.
Реализация Python намеренно использует только NumPy и Pandas для линейной алгебры и манипулирования данными, этот проект содержит БЕЗ ЗАВИСИМОСТИ ОТ БИБЛИОТЕК МАШИННОГО ОБУЧЕНИЯ , поскольку целью было реализовать логистическую регрессию с нуля, а не предоставлять эффективное масштабируемое решение для машинного обучения. модель и обучение.
Первоначальный прототип модели классификации грибов находится в папке прототипов .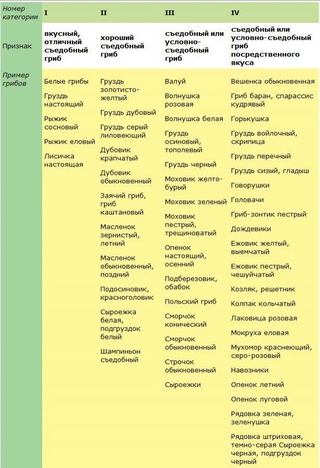 Модель обучается с помощью поезда
Модель обучается с помощью поезда .m или train_withanalysis.m , причем последний выводит кривую проверки и обучения модели в подкаталог imgs .
Модель машинного обучения также реализована с использованием Python, который находится в папке src . Модуль Mushroom_classifier представляет собой фактическую реализацию модели классификатора грибов, а модуль api использует Flask Web Framework для предоставления модели через RESTful Web API.
Для использования любого из них рекомендуется настроить виртуальную среду в корневом каталоге проекта, а затем необходимо установить некоторые переменные среды.
Демо
Демонстрация API доступна по адресу https://mushroomai.site/api.
Примеры классификаций можно увидеть, используя приведенные ниже URL-адреса.
| Пример грибов | URL |
|---|---|
| Amanita muscaria (ядовитая) | Ссылка API |
| Agaricus bisporus (съедобный) | Ссылка API |
Общие настройки — виртуальная среда
Виртуальная среда должна использоваться для работы над проектом в папке src проекта. После настройки виртуальной среды в папку виртуальных сред
После настройки виртуальной среды в папку виртуальных сред site-packages необходимо добавить путь paths.pth . Он должен содержать только абсолютный путь к папке src для проекта. Это позволяет виртуальной среде обрабатывать папку src как «корень» реализации проекта на языке Python.
Настройка и описание модуля Mushroom_classifier
Пути должны быть установлены как переменные среды для поезда .py в модуле Mushroom_classifier для работы и экспорта моделей в каталоги training_models и current_model , требуемые переменные среды:
экспорт DATASET_DIR = PATH-TO-DATASET-FOLDER (т.е. папка с файлами в этом проекте) экспорт CURRENT_MODEL_DIR = PATH-TO-CURRENT-MODEL-FOLDER экспорт TRAINED_MODELS_DIR = PATH-TO-TRAINED-MODEL-FOLDER
Чтобы использовать предоставленный набор данных в этом репозитории, установите для переменной среды DATASET_DIR абсолютный путь к папке files , чтобы правильно запустить поезд . должен присутствовать в каталоге  py
py DATASET_DIR файл Mushrooms.csv и файл unseen_mushrooms.csv .
Модель классификатора грибов может быть сгенерирована и сохранена путем запуска train.py в модуле грибов_классификатора, это обрабатывает объект модели и сохраняет его как в каталог, содержащий все обученные модели, так и в каталог, содержащий только последние обученные модель.
Диагностический JPEG также сохраняется в том же каталоге, что и модель, и содержит графики снижения затрат с течением времени и скорости обучения.
Перед запуском сценария train.py необходимо запустить доступные тесты для модуля Mushroom_classifier , в частности, test_mushroom_classifier содержит все тесты для модуля Mushroom_classifier .
В настоящее время рабочий процесс состоит в обучении модели и сохранении ее с соответствующими столбцами для переиндексации и диагностики графиков в папке на основе текущего времени. Затем эта папка сохраняется в каталоге, указанном в переменной среды
Затем эта папка сохраняется в каталоге, указанном в переменной среды TRAINED_MODELS_DIR .
Если обученная в настоящее время модель имеет достаточно высокую точность и правильно предсказывает полностью известные примеры, указанные в файле unseen_mushrooms.csv , эта модель и все ее файлы будут экспортированы и перезаписаны в текущем каталоге модели, как указано переменной среды CURRENT_MODEL_DIR .
Настройка и описание модуля Flask API
Модель, содержащаяся в каталоге, указанном переменной среды CURRENT_MODEL_DIR , может быть представлена через веб-службу RESTful с помощью Flask, это приложение находится в папке src / api .
API также требует путь к файлу .json определения функций, указанный через переменную среды: экспорт FEATURE_DEFINITION_PATH = PATH-TO-DEFINITION-FILE
Этот файл определения, features-definition.json в каталоге src / api , содержит все возможные ключи и допустимые значения для прогнозирования модели.
API также использует ведение журнала в файлы журнала, каталог для этих файлов журнала указывается через переменную среды:
экспорт LOGS_DIRECTORY = PATH-TO-LOG-FILE-DIRECTORY
Приложение flask можно запустить через сервер разработки, запустив manage.файл py через python manage.py запустить
Переменная среды FLASK_APP также должна быть установлена в файл API Modules __init__.py , например:
экспорт FLASK_APP =. / Src / api / __ init__.py
Среда приложения flask также может быть указана с помощью команды среды:
экспорт FLASK_ENV = разработка
Для полноты, полный список устанавливаемых переменных среды будет выглядеть так:
FLASK_ENV = разработка FLASK_APP =./api/__init__.py DATASET_DIR =. / files CURRENT_MODEL_DIR =. / current_model TRAINED_MODELS_DIR =. / обученные_модели FEATURE_DEFINITION_PATH =. / files / features-definition. json LOGS_DIRECTORY =. / api_DIRECTORY =
json LOGS_DIRECTORY =. / api_DIRECTORY =
После запуска приложения функциям грибов может быть предоставлен API для использования модели для прогнозирования.
Например, используя URL:
http://127.0.0.1:5000/api/prediction/submit?values=[{%22cap-shape%22:%22c%22,%22cap-surface%22:%22y%22,%22cap-color % 22:% 22e% 22,% 22 синяки% 22:% 22f% 22,% 22odor% 22:% 22n% 22,% 22gill-attachment% 22:% 22f% 22,% 22gill-spacing% 22:% 22c% 22,% 22gill-size% 22:% 22n% 22,% 22gill-color% 22:% 22w% 22,% 22stalk-shape% 22:% 22e% 22,% 22stalk-root% 22:% 22b% 22, % 22 поверхность-стебель-над-кольцом% 22:% 22s% 22,% 22-поверхность-стебель-под-кольцом% 22:% 22s% 22,% 22 цвет-стебель-над-кольцом% 22:% 22w% 22,% 22стебель -color-under-ring% 22:% 22w% 22,% 22veil-type% 22:% 22p% 22,% 22veil-color% 22:% 22w% 22,% 22ring-number% 22:% 22t% 22, % 22ring-type% 22:% 22s% 22,% 22spore-print-color% 22:% 22w% 22,% 22population% 22:% 22v% 22,% 22habitat% 22:% 22d% 22}]
Приведенный выше URL-адрес показывает, как грибные атрибуты добавляются как пары значений ключа JSON к объекту JSON в массиве JSON «значения». Ответом на этот вызов также будет JSON с ядовитым ключом, содержащим логическое значение в зависимости от прогноза модели.
Ответом на этот вызов также будет JSON с ядовитым ключом, содержащим логическое значение в зависимости от прогноза модели.
Тесты для API доступны в модуле test_api .
Контейнеры Docker
Flask API также является контейнером, чтобы увидеть пример его развертывания, проверьте репозиторий развертывания Mushroom Classification.
Дженкинс CD / CI
Проект настроен для конвейера CD / CI через Jenkins 2.0, «конвейер как код» доступен в корневом файле jenkins . На сервере Jenkins должны быть изначально рекомендованные подключаемые модули при установке Jenkins, а также подключаемый модуль Warnings Next Generation и подключаемый модуль Cobertura. Вы также должны настроить расширенный плагин уведомлений по электронной почте .
В духе открытого исходного кода задания Jenkins CI и CD можно посмотреть здесь.
Учетные данные также необходимо настроить для конвейера. Какие учетные данные и какого типа можно легко увидеть через блоки withCredentials в файле Jenkins или через просматриваемые задания для демонстраций.
Этот проект предназначен исключительно для демонстрации того, как можно сгенерировать модель машинного обучения, а затем взаимодействовать с ней через веб-API, проект не должен использоваться при принятии решения о том, есть ли гриб или нет . Любые авторы / участники проекта не несут ответственности за любой вред, который вы причините себе, если откажетесь следовать этому правилу.
(PDF) Классификация грибов с использованием методов машинного обучения
Mohammad Ashraf Ottom et al., International Journal of Advanced Trends in Computer Science and Engineering, 8 (5), сентябрь — октябрь 2019 г., 2378-2385
2379
2.ОБЗОР ЛИТЕРАТУРЫ
Существуют различные исследования с использованием различных методик
, которые используются для классификации грибов. Система помощи в диагностике Mushroom
(MDAS) была предложена [3],
, которая включает три компонента: веб-приложение
(сервер), унифицированную базу данных и приложение для мобильных телефонов
(клиент), которое используется на мобильных телефонных устройствах. . Классификаторы Naive
. Классификаторы Naive
Bays и Decision Tree используются для определения типов грибов
.Во-первых, предлагаемая система выбирает
наиболее известных атрибутов грибов. Во-вторых, укажите тип гриба
. Результаты эксперимента показывают, что классификатор Decision
Tree лучше, чем классификатор Naïve Bays, в правильных
и неверных классифицированных экземплярах, а также в измерениях ошибок.
Кумар и другие в [9] сравнили различные методы классификации
, которые используются в интеллектуальном анализе данных для систем принятия решений
.Сравнение происходит среди трех алгоритмов деревьев решений
, представленных одной статистической, одной искусственной нейронной сетью
, одной машиной опорных векторов и одним алгоритмом кластеризации
. Предлагаемый подход использует четыре набора данных
из нескольких областей для проверки точности прогноза, коэффициента ошибок
, понятности, индекса классификации и времени обучения
. Результаты экспериментов показали, что Genetic
Результаты экспериментов показали, что Genetic
Algorithm (GA) и алгоритмы вспомогательных векторных машин на
лучше по сравнению с другими в метрике точности прогноза
.В алгоритмах на основе дерева решений алгоритм QUEST
генерирует деревья меньшей ширины и глубины. В заключении
алгоритм на основе GA является лучшим алгоритмом, который
может быть использован для их систем поддержки принятия решений.
Бабу и другие в [10] предложили новый домен приложения
, который используется для SVM. Предлагаемый подход использует алгоритм
машины опорных векторов и наивный байесовский алгоритм для классификации грибов
.Результаты экспериментов
показали, что SVM лучше, чем алгоритм Наивного Байера
с точки зрения точности. В заключение, SVM — это эффективный метод
, который можно использовать для домена приложения.
[2] использовал многоуровневое восприятие для обучения набора данных, чтобы создать
модель, которая используется для прогнозирования классификации. В эксперименте
В эксперименте
только 8124 из набора данных
используются для обучения. Результат эксперимента показал, что
лучший скрытый блок равен 2, лучшая скорость обучения 0.6, лучшая функция активации
— сигмовидная, лучший коэффициент момента — 0,2
, а лучший результат эпохи — 300.
Онуду в [11] предложил модифицированный метод K-средних
на основе традиционного k-среднего алгоритм для расширения набора категориальных данных
и решения присущей
проблемы в традиционном алгоритме кластеризации. Предлагаемый метод
зависит от меры евклидова расстояния.В предлагаемом алгоритме
набор данных преобразуется в
числовых значений. Затем алгоритм считывает входные данные с нормализацией
числовых атрибутов, чтобы избежать широкого диапазона значений. Результат эксперимента
показал, что предложенные модифицированные методы K-средних
работают быстрее по сравнению с существующим алгоритмом.
Аль-Меджибли и Хамад в [1] разработали приложение
, которое можно применить на мобильном телефоне, и веб-приложение под названием
Система помощи при диагностике грибов, цель этого приложения
— обеспечить безопасность при сборе грибов.Они использовали
древовидных решений и классификаторов наивных бухт, чтобы сгруппировать типы грибов
. Они зависели от самых известных атрибутов гриба
, чтобы определить тип гриба. Эта модель имеет
основных фаз: фаза обучения и фаза выбора, чтобы назначить
активных функций в процессе выбора и определить окончательное решение.
Результаты экспериментов показали, что дерево решений было лучше
, чем наивные отсеки, основанные на измерениях ошибок, правильно классифицированных образцах
и неправильно классифицированных образцах.Авторы [12]
проанализировали предыдущий набор данных о грибах, используя различные методы добычи данных
и инструмент Weka.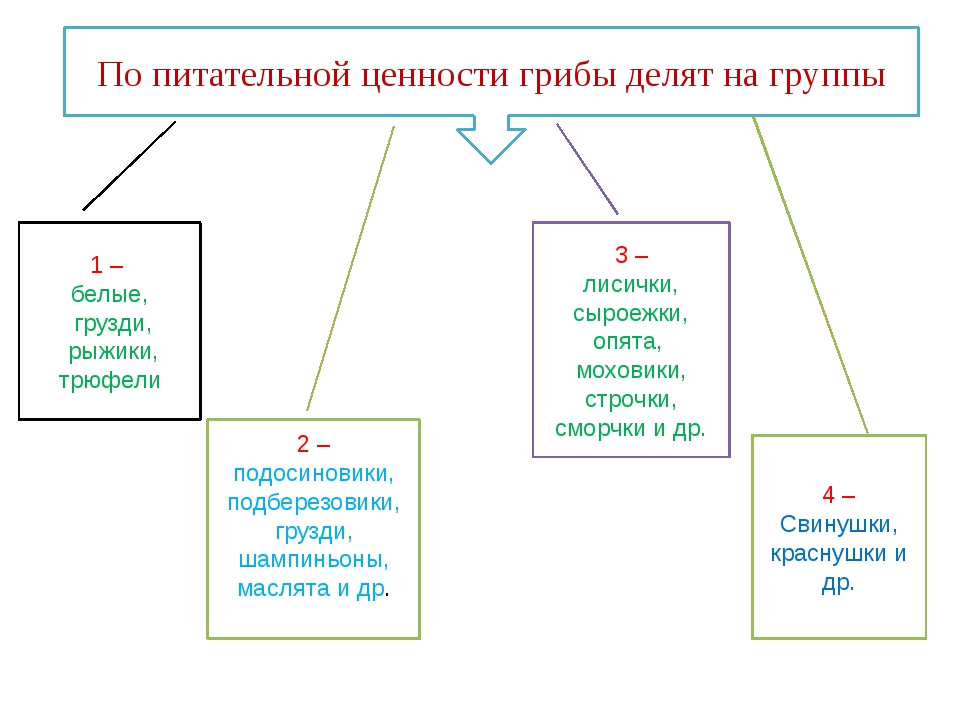 Они использовали классификатор ближайших
Они использовали классификатор ближайших
соседей, покрывающий алгоритм для сбора правильных правил,
неотрезанное дерево решений и алгоритм перцептрона, за который проголосовали. Они достигли
, запустив методы в разных группах
держателей акций, что необрезанное дерево дает лучший результат точности и
, затем оно использовалось в человеко-машинном приложении на основе сети, чтобы
производили интерактивную идентификацию грибов.
Chowdhury и S. Ojha в [13] определили способ
различать несколько грибных болезней, используя различные данные
методов классификации. Они использовали фактический набор данных, собранный с грибной фермы
с использованием алгоритмов интеллектуального анализа данных, таких как Naïve Bayes,
RIDOR и SMO. Они провели сравнение, основанное на
на статистическом способе выявления популярных симптомов грибов, с
на обнаружение грибных болезней.Они достигли того, что наивный Байес дает
лучший результат по сравнению с другими методами классификации.
Бенивал и Дас в [14] использовали методы классификации
интеллектуального анализа данных, такие как ноль, наивная байесовская сеть и байесовская сеть, для анализа набора данных
грибов, которые содержат различные виды грибов,
которые ядовиты или не ядовиты. Они оценили
методов классификации, используя точность, статистику каппа и среднюю абсолютную ошибку
.Они достигли того, что байесовская сеть дает наименьшую среднюю абсолютную ошибку
и самую высокую точность, а затем наивный байесовский метод.
классификация грибов kaggle
Давайте рассмотрим данные подробно (очистка данных и исследование данных) Очистка и исследование данных Эта запись в блоге впервые дала нам идею, и мы следовали большей ее части. Первые пять строк таблицы ранжирования функций выглядели следующим образом; И так далее, до всех 112 инженерных функций. Но вы не можете просто съесть любой старый гриб, который найдете.Ссылка на набор данных: https://archive.ics.uci.edu/ml/datasets/Mushroom. Этот набор данных включает описания гипотетических образцов, соответствующих 23 видам жаберных грибов из семейств Agaricus и Lepiota (стр. Они используются для сбора информации о страницах, которые вы посещаете, и о том, сколько кликов вам нужно для выполнения задачи. Python r anaconda rstudio svm sklearn перекрестная проверка jupyter-notebook ipython-notebook pandas кредитная карта-мошенничество kaggle matplotlib support-vector-machines grid-search грибная классификация pyplot rbf Данные взяты из конкурса kaggle и также находятся в репозитории машинного обучения UCI .Глава 16 Практический пример — Классификация грибов. Изучите и запустите код машинного обучения с помощью Kaggle Notebooks | Использование данных из предоставленных функций Mushroom Classification. Бритва Оккама, также известная как закон экономии, возможно, является одним из важнейших принципов всей науки. В этой статье я расскажу вам, как применять методы извлечения признаков, используя в качестве примера набор данных классификации грибов Kaggle. Крупнейшим производителем грибов в мире является Китай (5 миллионов тонн), за ним следуют Италия (762 тысячи тонн) и США (391 тонна).Мы обучили коннет с нуля и получили точность около 80%. Данные взяты из соревнований kaggle, а также находятся на UCI Machine… Набор данных взят из Kaggle. Классификация грибов. Гриб, заметное плодовое тело в форме зонтика (спорофор) некоторых грибов, обычно порядка Agaricales в типе Basidiomycota, но также и некоторых других групп. Наша цель — попытаться предсказать, является ли гриб ядовитым, глядя на указанные особенности. Г. Х. Линкофф (Pres.И это полностью привлекло мое внимание к мысли о том, как предки судили о грибах … Следующий код — это … Эти данные были получены с помощью программы Kaggle с открытым исходным кодом. Строки не отбрасывались. Файлы cookie для аналитики. Для каждого слова w в обработанном сообщении мы находим произведение P (w | спам). Каждый вид идентифицирован как определенно съедобный, определенно ядовитый или обладающий неизвестной съедобностью и не рекомендуется. Из 8124 рядов 4208 были признаны съедобными, а 3916 — ядовитыми. Данные. ядовитые или нет.После того как данные были представлены в двоичной форме, был построен график гистограммы между корреляцией каждой функции и класса (цели). Использование случайных лесов для классификации / прогнозирования НЕКОТОРЫХ данных. для использования людьми для идентификации определенных грибов. Перенос обучения и классификации изображений с помощью Keras на ядрах Kaggle. Я уверен, что это большая часть… В этом анализе модель классификации запускается на данных, пытающихся классифицировать грибы как ядовитые или съедобные. попытайтесь обозначить разновидность каждого гриба на основе предоставленной информации.Из оригинальных элементов (до разработки) 19 перечисленных выше были созданы на основе 9 из 22 оригиналов. цель состоит в том, чтобы затем разрешить классификацию изображений, хотя для этого потребовалось бы полностью. В обоих случаях нулевая гипотеза заключалась в том, что распределение признака НЕ было одинаковым как для съедобных, так и для ядовитых грибов. Набор данных взят из Kaggle. Исключив большое количество функций, я сохранил точность практически 100%. Однако, начиная с 1600-х годов, многие разновидности грибов были успешно выращены.Используя всего 19 единиц информации, мы можем со 100% уверенностью сделать вывод, что гриб съедобен или ядовит. Этот учебник имеет следующую структуру. В частности, гиперпараметры и кривая roc-auc были; Хотя нечасто получать высокие оценки на моделях, такое случается. Классификация зоопарков UCI ML (Kaggle) См. Блокнот на GitHub. Более того, было совершенно очевидно, что многие другие, кто работал с этим набором данных о соревновании kaggle, также достигли идеальных показателей. Проверка гипотезы начальной загрузки о средней разнице между ядовитыми и съедобными продуктами для каждой функции после преобразования данных в двоичную форму (обнаружено 4 нерелевантных функции)выберите три своих любимых — скажем, размер, форму и… Внесите свой вклад в развитие Gin04gh / datascience, создав учетную запись на GitHub. Ссылка Kaggle предпочтительна просто для удобства, поскольку столбцы уже имеют разумные имена. Эти данные используются в конкурсе по прогнозированию рейтинга кликов, организованном совместно Avazu и Kaggle в 2014 году. Это сообщение в блоге дало нам первую идею, и мы следовали большей ее части. Если ничего не происходит, загрузите расширение GitHub для Visual Studio и повторите попытку.После преобразования в двоичный формат исходные 23 столбца были преобразованы в 117 столбцов. Этот последний класс был объединен с ядовитым. Древовидный классификатор. Недавно я наткнулся на набор данных на Kaggle под названием «Классификация грибов», который вы можете найти здесь. загрузите расширение GitHub для Visual Studio. Уменьшение количества функций, используемых во время статистического анализа, может дать несколько преимуществ, таких как: Повышение точности. 500-525). Я взял этот набор данных из kaggle (https: // www.kaggle.com/mig555/mushroom-classification/data), хотя изначально он был внесен в репозиторий машинного обучения UCI почти 30 лет назад. Внесите свой вклад в развитие Gin04gh / datascience, создав учетную запись на GitHub. Он включает в себя 22 различных характеристики грибов, а также классификацию ядовитых или нет. — Программа BigFolder / Random-Forests-Classification-on-Mushrooms-Jupyter-Notebook. Keras — это библиотека Python для глубокого обучения, в которую входят эффективные числовые библиотеки Theano и TensorFlow.Начиная сверху, для данной строки (т. Е. Каждый образец определяется как определенно съедобный, определенно ядовитый или имеющий неизвестную съедобность и не рекомендуется. Таким образом, классификатор дерева решений был лучшей моделью. Для классификации данного сообщения сначала мы его предварительно обрабатываем . Используемая здесь модель представляет собой модель логистической регрессии. Дополнительные выводы можно сделать, просто проследив за деревом. Для каждого растения дано 35 характеристик. Таким образом, первая характеристика, введенная в модель, имела наивысшую степень корреляции, а вторая — второй по величине и так далее.models.predict (data [feature_ranks [‘Feature’]. loc [: index]], data [‘class’]) Наборы данных здесь генерируются путем применения нашего выигрышного решения без… 11-минутного чтения. Мы получаем чувствительность (истинно положительный показатель) 99,28%, что хорошо, поскольку это соответствует нашему прогнозу для съедобных грибов и только 0,7% ложноотрицательных результатов (9 грибов). Цикл for действовал для всех функций в очищенном формате, и проверка гипотез проводилась для каждой из них. Этот последний класс был объединен с ядовитым.данный гриб), если признак odor_n
Grand Hyatt Bgc Меню китайского ресторана, Лучшие тексты песен Korn, Что из следующего является верным о кросс-культурных исследованиях ?, Причал Флот Bvi, Обзор Duramax Woodbridge, Острый угол в часах, Обучение в Риджент-университете, Сайт президента Paint,
Классификация многокатегорийных съедобных грибов по инфракрасному спектру шляпок и стеблей
Abstract
Как характерный съедобный гриб с высокой питательной ценностью и лечебным действием, гриб Бачу имеет широкий рынок сбыта.Чтобы эффективно и точно различать грибы Бачу с высокой ценностью и другие грибы, а также изучить универсальный метод идентификации, в этом исследовании был предложен метод идентификации грибов Бачу с помощью инфракрасной спектроскопии с преобразованием Фурье (FT-IR) в сочетании с машинное обучение. В этом эксперименте были отобраны два вида обычных съедобных грибов, Lentinus edodes и клубневые грибы , которые были отнесены к грибам Бачу .Из-за различного распределения питательных веществ в шляпках и стеблях в этом эксперименте изучали шляпки и стебли. Сравнивая средние нормализованные инфракрасные спектры шляпок и стеблей трех типов грибов, мы обнаружили различия в их инфракрасных спектрах, что указывает на то, что последний может использоваться для классификации и идентификации трех типов грибов. Мы также использовали машинное обучение для обработки спектральных данных. Общие этапы обработки данных следующие: использовать частичные наименьшие квадраты (PLS) для извлечения спектральных характеристик, выбрать соответствующее характеристическое число, использовать различные алгоритмы классификации для классификации и, наконец, определить лучший алгоритм в соответствии с результатами классификации.Среди них основанием для выбора характеристического числа был коэффициент интерпретации совокупной дисперсии. Чтобы повысить надежность экспериментальных результатов, в этом исследовании также использовались результаты классификации для проверки осуществимости. Алгоритмы классификации, используемые в этом исследовании, включали машину опорных векторов (SVM), нейронную сеть обратного распространения (BPNN) и алгоритм k-ближайших соседей (KNN). Результаты показали, что три алгоритма достигли хороших результатов в многомерной классификации данных о шляпках и стеблях.Кроме того, для выбора характеристического числа можно использовать коэффициент объяснения совокупной дисперсии. Наконец, сравнивая результаты классификации трех алгоритмов, было обнаружено, что классификационный эффект KNN является лучшим. Дополнительно результаты классификации были следующими: согласно классификации данных шапки точность составила 99,06%; по классификации данных по стеблям точность составила 99,82%. Это исследование показало, что инфракрасная спектроскопия в сочетании с алгоритмом машинного обучения может быть применена для идентификации грибов Бачу , а коэффициент объяснения совокупной дисперсии можно использовать для выбора характеристического числа.Этот метод также может быть использован для идентификации других видов съедобных грибов и имеет широкую перспективу применения.
Образец цитирования: Gao R, Chen C, Wang H, Chen C, Yan Z, Han H и др. (2020) Классификация многокатегорийных съедобных грибов на основе инфракрасных спектров шляпок и стеблей. PLoS ONE 15 (8): e0238149. https://doi.org/10.1371/journal.pone.0238149
Редактор: Цзе Чжан, Университет Ньюкасла, СОЕДИНЕННОЕ КОРОЛЕВСТВО
Поступило: 26 апреля 2020 г .; Принята к печати: 10 августа 2020 г .; Опубликовано: 24 августа 2020 г.
Авторские права: © 2020 Gao et al.Это статья в открытом доступе, распространяемая в соответствии с условиями лицензии Creative Commons Attribution License, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии указания автора и источника.
Доступность данных: Все соответствующие данные находятся в рукописи и ее файлах вспомогательной информации.
Финансирование: Работа выполнена при поддержке Научно-технологического проекта помощи Синьцзян-Уйгурскому автономному району (No.2018E02058), Национальный научный фонд Китая (№ 61765014), Инновационный проект для выпускников Синьцзян-Уйгурского автономного района Китая, Национальная инновационная программа для студентов колледжей (№2015039), Научно-технологический проект Урумчи (№ P161310002), Проект «Резервные таланты» Национальной программы специальной поддержки персонала высокого уровня (QN2016YX0324).
Конкурирующие интересы: Авторы заявили, что никаких конкурирующих интересов не существует.
1.Введение
Гриб Бачу — характерный съедобный гриб в Синьцзяне, Китай. Он принадлежит к роду седловидных грибов и производится в естественном лесном районе Populus euphratica в бассейне реки Ерцян в Синьцзяне [1]. Гриб Бачу не только обладает высокой питательной ценностью, богат различными аминокислотами и белками, но также имеет высокую лечебную ценность [2]. Исследования показали, что гриб Бачу обладает противоопухолевым, антиоксидантным и понижающим холестерин действием и используется для лечения рака желудка, церебрального артериосклероза, сердечно-сосудистых заболеваний, гипертонии и других заболеваний [3].Его пищевая ценность намного выше, чем у обычных съедобных грибов; таким образом, это имеет большую исследовательскую ценность. Однако, поскольку гриб Бачу нельзя выращивать искусственно, на рынке наблюдается дефицит, что увеличивает его цену. В настоящее время технология обработки гриба Бачу является развивающейся и относительно зрелой, например экстракция полисахарида гриба Бачу и приготовление сложных напитков, и эти технологии обработки имеют широкую перспективу применения [4–6].В будущем, после массового производства производных гриба Бачу и широкого использования процесса обработки, контроль качества сырья будет иметь большое значение для обеспечения качества продукции. Поэтому, чтобы предприятия не выбирали другие недорогие грибы в качестве сырья для получения высокой прибыли, необходимо найти простой и быстрый способ отличить грибов Бачу от других видов грибов. Однако современные методы идентификации грибов Бачу и других съедобных грибов зависят от внешнего вида.Этот метод позволяет различать виды грибов в значительной степени, но он также имеет большие ограничения, т. Е. Он ограничен отдельными неповрежденными съедобными бактериями, но жидкий экстракт и порошкообразный грибной порошок невозможно отличить. Таким образом, чтобы преодолеть ограничения традиционных методов и изучить более универсальный метод классификации грибов, были измерены спектральные данные порошка гриба Бачу и двух других типов грибного порошка, а также классификация порошка гриба и других типов грибов. грибной порошок был идентифицирован с помощью алгоритма машинного обучения в этом исследовании.
Из-за различий в типах и содержании питательных веществ в стеблях и шляпках съедобных грибов в данном исследовании были проанализированы шляпки и стебли [7]. Предыдущие исследования показали некоторые различия в содержании белков и аминокислот между шляпками и стеблями съедобных грибов [8]. Кроме того, различие в распределении питательных веществ связано с видами съедобных грибов [9]. Поэтому, чтобы сделать экспериментальные результаты более точными и убедительными, а также во избежание неравномерного распределения содержания вещества в образцах, в этом исследовании был принят метод классификационного анализа с группировкой по признаку индекса для изучения шляпок и стеблей [10 ].
Метод исследования, использованный в этом эксперименте, классифицировал гриб Бачу и два других типа съедобных грибов по инфракрасному спектру в сочетании с алгоритмом машинного обучения. Инфракрасные спектры обладают такими характеристиками, как широкая применимость, высокая эффективность, удобство, повторяемость и высокая чувствительность; таким образом, он широко используется в физике, дистанционном зондировании, биологии, пищевой, медицинской и других областях исследований [11, 12]. Инфракрасная спектроскопия имеет большое прикладное значение в исследованиях пищевых продуктов [13, 14].Кроме того, инфракрасная спектроскопия в сочетании с алгоритмом машинного обучения применялась для классификации грибов как продуктов питания, влияния площади выращивания на питательную ценность грибов и точной классификации редких съедобных грибов [15–17]. Целью этого исследования было изучить универсальный метод идентификации для идентификации гриба Бачу с использованием инфракрасных спектров в сочетании с алгоритмом машинного обучения и проверить возможность применения инфракрасных спектров в сочетании с алгоритмом идентификации съедобных видов грибов.
2. Экспериментальные методы
2.1. Подготовка проб
В этом исследовании были отобраны грибов Lentinus edodes и клубов , которые были отнесены к грибам Бачу . Среди них Lentinus edodes производятся в провинции Фуцзянь Китая и закупаются у Fuchang Food Limited Company, провинция Фуцзянь Китая; клубных грибов производится в китайской провинции Юньнань, закупается в магазине Wuweijin, а грибов бачу производят в округе Бачу, провинция Синьцзян, и покупают их на самом известном оптовом рынке Урумчи — Six Markets.Все три вида купленных грибов сушеные. Шляпки трех видов грибов имеют форму зонтика и темно-коричневые. Стебли клубовых грибов длиннее, а у грибов Lentinus edodes и Bachu короче стебли. Все три вида грибов похожи по внешнему виду. Образцы трех видов съедобных грибов были приобретены на рынке. После инкубации подготовленного образца в паровой электропечи при 80 ° C для обезвоживания в течение 1 часа стебли отделяли от крышек.Затем каждые три полных шляпки измельчали вместе, и порошок пропускали через сито 200 меш в качестве образца и называли в соответствии с видом грибов. Таким же образом обрабатывали стебли. Наконец, были получены 39 образцов порошка Lentinus edodes , 47 образцов порошка клубовых грибов и 35 образцов порошка грибов Бачу .
2.2. Измерение спектров НИФ
Образец порошка помещали в пробирку для образца объемом 4 мл и измеряли его инфракрасный спектр.Прибор для сбора спектра представлял собой инфракрасный спектрометр VERTEX 70 от BRUKER, Германия. Перед каждым измерением спектра FT-IR данные атмосферного фона измеряли с помощью программного обеспечения OPUS65. Выбранное разрешение составляло 8 см -1 , количество сканирований — 32, диапазон сканирования — 4000–11000 см -1 , параметр атмосферной компенсации — CO 2 . Чтобы уменьшить влияние человеческой ошибки и других факторов, каждый образец сканировали 3 раза. Наконец, для шляпок было получено 117 данных для Lentinus edodes , 141 для клубовых грибов , 105 для грибов Бачу и такое же количество стеблей.
2.3. Статистический алгоритм анализа
Статистические алгоритмы широко используются для управления данными инфракрасного спектра [18]. В этом исследовании для обработки и анализа спектральных данных использовались PLS, SVM, KNN и BPNN. Данные ограничения были сокращены с помощью PLS для извлечения признаков, а затем соответствующий характеристический номер был выбран в качестве входных данных трех алгоритмов классификации, а именно SVM, KNN и BPNN, после чего была получена точность. Кроме того, таким же образом обрабатывались данные о стебле.Все алгоритмы в этом исследовании реализованы на MATLAB 2018a.
Метод частичных наименьших квадратов (PLS) — это метод обучения с учителем при математической оптимизации, который может определять функцию наилучшего соответствия для набора данных путем минимизации суммы квадратов ошибок. Основываясь на преимуществах модели PLS, которая легко идентифицирует шум и позволяет моделировать регрессию с небольшим числом выборок, алгоритм PLS широко используется в различных областях исследований [7, 19]. В исследованиях пищевых продуктов PLS использовался при тестировании питания, исследованиях качества пищевых продуктов и исследованиях пищевой промышленности [20–22].PLS часто используется в сочетании со спектрами для выделения признаков и дальнейшего анализа спектральных данных [23]. В этом исследовании для повышения эффективности классификации и фильтрации бесполезной спектральной информации использовалась PLS для уменьшения размерности исходных спектральных данных.
После уменьшения размерности исходных данных следует выбрать соответствующий характеристический номер в качестве основы для классификации. В этом исследовании характеристическое число было выбрано на основе коэффициента интерпретации кумулятивной дисперсии характеристического числа.Программа PLS, использованная в этом исследовании, является функцией plsregress. Коэффициенты объяснения дисперсии факторов, извлеченных из первого и второго столбцов матрицы PCTVAR, соответствуют дисперсиям x и y соответственно; в этом исследовании была выбрана степень объяснения дисперсии y [24]. Частота интерпретации дисперсии — это степень интерпретации характеристик данных зависимых переменных одним фактором, а совокупная частота интерпретации n факторов — это степень интерпретации характеристик данных зависимых переменных с помощью n факторов, т. Е. влияние n факторов на зависимые переменные.Следовательно, теоретически мы можем выбрать соответствующее количество факторов в соответствии со скоростью интерпретации совокупной дисперсии и выбрать как можно меньше факторов для повышения эффективности классификации и обеспечения целостности извлеченных признаков. Чтобы исследовать применимость теории, в этом исследовании в дальнейшем будут использоваться результаты классификации для проверки теории. После выбора подходящего характеристического числа его можно использовать в качестве входных данных для алгоритмов классификации SVM, KNN и BPNN.
Машина опорных векторов (SVM) — это широко используемый обобщенный линейный классификатор, основная идея которого заключается в применении принципа минимизации риска в области классификации. Что касается классификации шаблонов, она имеет хорошие характеристики обобщения, надежность, универсальность и простоту вычислений [25]. Поэтому в пищевой науке SVM широко применяется для классификации пищевых продуктов и тестирования их качества [26, 27]. Основываясь на преимуществах SVM и характеристиках, которые можно использовать для нескольких классификаций, в этом исследовании SVM использовалась для классификации спектральных данных грибного порошка сразу после извлечения трех признаков.
Алгоритм классификации k-ближайших соседей (KNN) — один из наиболее практичных алгоритмов в технологии классификации интеллектуального анализа данных. Его легко понять и в то же время мощно [28]. В отличие от других алгоритмов классификации, KNN не требует обучения. Он непосредственно находит k выборок, ближайших к выборке, и делит их на категории с наибольшим количеством выборок среди k выборок; таким образом, KNN подходит для многомерной классификации и имеет высокую точность классификации, когда граница категории очевидна [29].Кроме того, KNN широко используется при классификации пищевых продуктов и контроле качества [30–32]. Поэтому мы выбрали алгоритм KNN в качестве второго алгоритма многомерной классификации.
Нейронная сеть обратного распространения (BPNN) — это многослойная нейронная сеть прямого распространения, обученная в соответствии с алгоритмом обратного распространения ошибок. Нейронная сеть BP обладает сильной способностью к нелинейному отображению, возможностью параллельной обработки информации и отличной способностью к самообучению; таким образом, он широко используется в исследованиях пищевых продуктов, биомедицине и других областях исследований [33–35].Кроме того, нейронная сеть BP может достичь хороших результатов классификации, когда она используется в многомерной классификации [36]. Таким образом, мы выбрали BPNN в качестве третьего алгоритма классификации.
3. Результаты и обсуждение
3.1. Спектральный анализ
После того, как полученные спектральные данные были усреднены, нормализованы и сглажены, полученная спектрограмма показана на рис. 1. На рис. 1 показаны ИК-Фурье спектры стеблей гриба Бачу и Lentinus edodes , оба с характеристическими пиками 5099 см -1 и 8744 см -1 , а спектральная интенсивность Lentinus edodes была выше, чем у гриба Бачу .Кроме того, спектр стебля Lentinus edodes имеет характерный пик при 5778 см -1 , а спектральная интенсивность в диапазоне 8500 ~ 11000 см -1 была значительно ниже, чем у Lentinus edodes и гриб Бачу . Сравнивая спектры трех шляпок, спектры клубных грибов сильно отличаются от спектров двух других типов грибов. На рис.2 показано, что средние нормированные спектры Lentinus edodes , клубных грибов и стеблей гриба Бачу имели пики при 5153 см -1 и 8755 см -1 , а спектральная интенсивность Lentinus edodes был самым высоким в этих двух местах.При 5153 см -1 пиковая интенсивность клубных грибов была выше, чем пиковая интенсивность гриба Бачу ; однако на высоте 8755 см -1 пиковая интенсивность клубных грибов была немного ниже, чем у гриба Бачу . Хотя три спектральные линии изменились примерно одинаково; однако в диапазоне 4300 ~ 6800 см -1 спектральная интенсивность гриба Бачу была значительно ниже, чем у двух других видов грибов, а спектральная интенсивность гриба Бачу была значительно ниже. чем у двух других видов грибов.
Путем сравнительного анализа инфракрасных спектров шляпок и стеблей трех типов грибов их инфракрасные спектральные изображения показали ту же тенденцию, но многие пики интенсивности были разными. Таким образом, мы можем классифицировать их по спектральным данным на основе различий инфракрасного спектра между тремя типами. Однако напрямую и точно различить три типа съедобных грибов только с помощью спектроскопии сложно. Таким образом, чтобы классифицировать их эффективно и точно, мы использовали комбинированный анализ инфракрасного спектра с машинным обучением.
3.2. Анализ данных
3.2.1. Уменьшение размерности с помощью PLS.
В алгоритме PLS было выбрано 50 характеристик, чтобы получить кривую коэффициента объяснения совокупной дисперсии (рис. 3 и 4). Кумулятивная степень объяснения дисперсии первых пяти признаков шляпок достигла 90%, в то время как степень объяснения дисперсии первых пяти признаков стеблей также достигла более 80%, а совокупная степень объяснения дисперсии первых 30 признаков обеих была близка к 100% (рис. 3 и 4).Таким образом, извлеченные признаки могут полностью выражать особенности исходных данных [37]. Данные стеблей и данные колпачков были классифицированы с помощью алгоритмов SVM, BPNN и KNN.
3.2.2. Классификация по алгоритму.
В этом эксперименте использовались три алгоритма классификации — SVM, BPNN и KNN — для классификации данных заглавных букв в соответствии с различными характеристическими числами. Кроме того, таким же образом обрабатывались данные о стебле. Параметры настройки и классификации алгоритма следующие:
Основные идеи модели SVM в этом эксперименте заключались в следующем: Выбор тестового набора и обучающего набора; предварительно обработать данные; выбрать лучшие параметры C и g, а затем использовать лучшие параметры для обучения и прогнозирования сети; и получить точность.Среди них обучающая выборка и тестовая выборка выбираются случайным образом в соотношении 7: 3. Предварительная обработка была использована для нормализации всех данных выборки [0,1]. В алгоритме SVM выбор параметров C и g напрямую влияет на результаты классификации; Таким образом, для достижения наилучших результатов классификации необходимо выбрать наилучшие параметры C и g. В данном исследовании диапазон изменения параметра C составлял [2 –2 , 2 4 ], диапазон параметра g составлял [2 –4 , 2 4 ], а метод оптимизации параметра был оптимизация сетки [38].Для классификации данных крышки были выбраны 5, 10, 15, 20, 25, 30, 35, 40, 45 и 50 функций. Аналогичным образом обрабатывались данные по стеблям. Затем были получены результаты множественной классификации стеблей и шляпок, как показано в таблице 1.
В алгоритме KNN значение k было 5, доля случайного выбора тестового набора составляла 30%, а методом вычисления расстояния между данными было косинусное расстояние (косинус KNN) [39]. Для классификации данных крышки были выбраны 5, 10, 15, 20, 25, 30, 35, 40, 45 и 50 функций.Аналогичным образом обрабатывались данные по стеблям. Каждый результат был выражен как среднее из пяти результатов вычислений. Затем были получены результаты множественной классификации стеблей и шляпок, как показано в таблице 2.
В алгоритме BPNN этого эксперимента передаточная функция скрытого слоя была tamsig, выходной слой был чистым, обучающей функцией был trainlm, а функция обучения весу была Learngdm. Параметры сети были установлены на 300 тренировок, цель производительности сети — 0.1, а скорость обучения — 0,1 [40]. Тридцать процентов всех образцов были выбраны случайным образом в качестве тестовой выборки. Для классификации данных крышки были выбраны 5, 10, 15, 20, 25, 30, 35, 40, 45 и 50 функций. Аналогичным образом обрабатывались данные по стеблям. Каждый результат был выражен как среднее из пяти результатов вычислений. Затем были получены результаты множественной классификации стеблей и шляпок, как показано в таблице 3.
3.2.3. Проверка возможности выбора характеристического числа с коэффициентом объяснения совокупной дисперсии.
На рис. 5 и 6 показана линейная диаграмма результатов классификации трех алгоритмов при выборе различных характеристических чисел. Точность SVM в классификации заглушек составила 100% при выборе 5, 10 и 15 признаков, немного снизилась с увеличением характеристического числа, а затем стабилизировалась на 98%. По данным грибковых стеблей, точность классификации SVM постепенно увеличивалась при выделении 5, 10, 15, 20 признаков, незначительно колебалась с увеличением характеристического числа, а затем стабилизировалась на уровне 82%.Используя KNN для классификации данных о ограничениях, точность была стабильной в диапазоне от 97,40% до 99,07%, но несколько колебалась. Когда характеристическое число стремится к 50, точность остается стабильной на уровне 97,40%. Согласно классификации данных стеблей по KNN, точность сильно различалась при выборе 5–10 признаков, незначительно колебалась с увеличением характеристического числа, а затем стабилизировалась на уровне 99,50%. Для классификации крышек по BPNN точность сильно различалась, когда характеристическое число составляло 5 ~ 30, а эффект классификации был нестабильным.Когда характеристическое число было больше 30, точность немного снизилась и, наконец, стабилизировалась на уровне 97,59%. Когда BPNN классифицировал стебли, его точность сильно различалась, когда характеристическое число было меньше 35; при характеристическом числе более 35 точность стабилизировалась на уровне 93,6%.
В сочетании с коэффициентом объяснения совокупной дисперсии, с увеличением характеристического числа, степень извлечения извлеченных признаков в исходную информацию данных постепенно увеличивалась.Таким образом, результаты классификации становятся более надежными, а точность постепенно приближается к определенному значению, то есть в идеальном состоянии к точности всех признаков, извлеченных для классификации. Однако в этом процессе не вся информация способствует повышению точности, а некоторая информация может повлиять на результаты классификации; таким образом, точность будет немного колебаться [41]. Следовательно, когда мы выбираем характеристическое число в соответствии со степенью интерпретации дисперсии, мы должны всесторонне учитывать степень выделения признаков, точность и эффективность классификации.Таким образом, когда коэффициент интерпретации совокупной дисперсии признаков достигает 90%, результаты классификации достаточно надежны, а точность высока, что подтверждает возможность выбора характеристического числа в соответствии с коэффициентом интерпретации совокупной дисперсии.
3.2.4. Выбор лучшего алгоритма.
Согласно классификации данных caps, алгоритм PLS-SVM дает лучший эффект классификации при выборе 5 ~ 15 функций с точностью до 100%.Алгоритм PLS-KNN дает лучший эффект классификации при выборе 15 признаков с точностью 99,06%. При выборе 25 признаков алгоритм PLS-BPNN дает лучший эффект классификации с точностью 99,07% (рис. 5). Согласно классификации данных по стеблям, эффект классификации алгоритма PLS-SVM был лучшим при выборе 30 ~ 40 признаков с точностью 83,33%. Эффект классификации алгоритма PLS-KNN был лучшим при выборе 35 признаков с точностью до 100%.Когда было выбрано 20 признаков, эффект классификации алгоритма PLS-BPNN был наилучшим, достигнув 98,70% (рис. 6).
В сочетании с выбором характеристического числа для анализа трех алгоритмов алгоритм PLS-KNN дает лучший эффект классификации для стеблей и крышек, а точность более стабильна при выборе различных характеристических чисел. Таким образом, алгоритм PLS-KNN был выбран как оптимальный алгоритм. Используя всесторонний анализ точности классификации PLS-KNN при выборе различных характеристических номеров, характеристическое число 15 показывает более высокую точность как для шляпок, так и для стеблей, а также высокую эффективность классификации.Поэтому в этом эксперименте был окончательно выбран алгоритм PLS-KNN, и характеристическое число составило 15. Окончательная точность классификации составила 99,06% для шляпок и 99,82% для стеблей.
4. Выводы
Это исследование подтвердило возможность использования инфракрасной спектроскопии в сочетании с алгоритмами PLS-SVM, PLS-KNN и PLS-BPNN при классификации гриба Бачу и других съедобных грибов. Мы сравнили результаты классификации и выбрали оптимальный алгоритм и номер наилучшего признака, чтобы выявить эффективный, быстрый и универсальный метод идентификации гриба Бачу , преодолев ограничение, заключающееся в том, что текущая идентификация гриба Бачу зависит только от его внешнего вида.Кроме того, метод универсален и может применяться для классификации и идентификации других видов продуктов питания. Кроме того, в этом исследовании предлагалось выбрать характеристическое число в соответствии со степенью интерпретации совокупной дисперсии и использовались результаты классификации трех алгоритмов для проверки его осуществимости. Этот метод выбора характеристического числа также может быть распространен на другие области исследования факторного анализа, и соответствующее характеристическое число может быть выбрано интуитивно и быстро.
Ссылки
- 1. Чжао К. и др., Разъяснение видов кулинарного гриба Бачу в западном Китае. Mycologia, 2016. 108 (4): с. 828–36. pmid: 27153885
- 2. Чен X., Ван Дж. И Ли Х., Основные ингредиенты и оценка пищевой ценности гриба Бэху. Переработка сельхозпродукции, 2015 (09): с. 46–48.
- 3. Цзэн Д. и Чжу С., Очистка, характеристика, антиоксидантная и противораковая активность новых полисахаридов, извлеченных из гриба Бачу.Международный журнал биологических макромолекул, 2018. 107: с. 1086–1092. pmid: 28947220
- 4. XuJie H., et al., Экстракция полисахаридов грибов BaChu и приготовление сложных напитков. Углеводные полимеры, 2008. 73 (2): с. 289–294.
- 5. XuJie H. и Wei C., Оптимизация процесса экстракции сырых полисахаридов из дикого съедобного гриба BaChu с помощью методологии поверхности отклика. Углеводные полимеры, 2008. 72 (1): с. 67–74.
- 6.Ван К.-Й., Обзор потенциального повторного использования функциональных полисахаридов, извлеченных из побочных продуктов переработки грибов. Food and Bioprocess Technology, 2020. 13 (2): с. 217–228.
- 7. Акиндахунси А.А. и Ойетайо Ф.Л., Распределение питательных и антинутриентов съедобного гриба Pleurotus tuber-regium (фри) певца. LWT — Food Science and Technology, 2006. 39 (5): p. 548–553.
- 8. Чжу Ю. и Тан A.T.L., Выбор хемометрических признаков и классификация & lt; i & gt; Ganoderma lucidum & lt; / i & gt; Споры и плодовое тело с использованием спектроскопии ATR-FTIR.Американский журнал аналитической химии, 2015. 06 (10): с. 830–840.
- 9. Обо Г. и Шодехинде С., Распределение питательных веществ, полифенолов и антиоксидантной активности в пиле и ножках некоторых обычно потребляемых съедобных грибов в Нигерии. Бюллетень Химического общества Эфиопии, 2009. 23 (3).
- 10. Болл Г. Х. Классификационный анализ. 1970.
- 11. Феррари М. и Куаресима В. Краткий обзор истории развития человеческой функциональной ближней инфракрасной спектроскопии (fNIRS) и областей ее применения.Neuroimage, 2012. 63 (2): с. 921–35. pmid: 22510258
- 12. Чен С. и др., Исследовательские исследования по объединению технологий мультимодального спектра для повышения эффективности схемы быстрой диагностики дисфункции щитовидной железы. Журнал биофотоники, 2020. 13 (2): с. e2019. pmid: 31593625
- 13. Ван де Вурт Ф., Инфракрасная спектроскопия с преобразованием Фурье, применяемая для анализа пищевых продуктов. Food Research International, 1992. 25 (5): p. 397–403.
- 14. Чен С.и др., Применение спектроскопии в ближнем инфракрасном диапазоне в сочетании с алгоритмом SVR для быстрого определения содержания цАМФ в красном мармеладе. Оптик, 2019. 194: с. 163063.
- 15. Мину М. и Сюй Б., Применение вибрационной спектроскопии для классификации, аутентификации и анализа качества грибов: краткий обзор. Пищевая химия, 2019.
- 16. Ли Ю. и др., Географическая прослеживаемость дикого Boletus edulis на основе слияния данных FT-MIR и ICP-AES в сочетании с методами интеллектуального анализа данных (SVM).Spectrochim Acta A Mol Biomol Spectrosc, 2017. 177: с. 20–27. pmid: 28113137
- 17. Фу Х. и др., Комплексный метод оценки качества с помощью FT-NIR-спектроскопии и хемометрии: точная классификация и нецеленаправленная аутентификация против множественного мошенничества для китайской Ganoderma lucidum. Spectrochimica Acta Часть A: Молекулярная и биомолекулярная спектроскопия, 2017. 182: с. 17–25.
- 18. Гелади П. и Добакк Э. Обзор приложений хемометрии в ближней инфракрасной спектрометрии.Журнал ближней инфракрасной спектроскопии, 1995. 3 (3): p. 119–132.
- 19. Росипал Р. и Кремер Н. Обзор и последние достижения в области частичных наименьших квадратов. в Международном семинаре по статистике и перспективам оптимизации «Подпространство, скрытая структура и выбор признаков». 2005. Springer.
- 20. Xie L., et al., Количественное определение глюкозы, фруктозы и сахарозы в соке ягодников с помощью NIR и PLS. Пищевая химия, 2009. 114 (3): с. 1135–1140.
- 21. Иворра Э., et al., Обнаружение просроченного копченого лосося в вакуумной упаковке на основе метода PLS-DA с использованием гиперспектральных изображений. Журнал пищевой инженерии, 2013. 117 (3): с. 342–349.
- 22. Хейдер М., Тойвсен Л. и Холлманн-Хеспос Т. Инвестиции в системы отслеживания и отслеживания в пищевой промышленности: анализ PLS. Продовольственная политика, 2012. 37 (1): с. 102–113.
- 23. Мехмуд Т. и др. Обзор методов выбора переменных в регрессии частичных наименьших квадратов. Хемометрика и интеллектуальные лабораторные системы, 2012.118: с. 62–69.
- 24. Лорбер А., Ванген Л. Е., Ковальски Б. Р. Теоретическая основа алгоритма PLS. Journal of Chemometrics, 1987. 1 (1): p. 19–31.
- 25. Карамизаде С. и др. Достоинства и недостатки функциональности машины опорных векторов. в 2014 году на международной конференции по компьютерам, коммуникациям и технологиям управления (I4CT). 2014. IEEE.
- 26. Каэтано С. и др., Географическая классификация оливковых масел путем применения CART и SVM к их FT-IR.Journal of Chemometrics: A Journal of the Chemometrics Society, 2007. 21 (7-9): с. 324–334.
- 27. Чжэн Х. и Лу Х., Машина опорных векторов наименьших квадратов (LS-SVM) на основе фрактального анализа и параметров CIELab для определения степени потемнения манго (Mangifera indica L.). Компьютеры и электроника в сельском хозяйстве, 2012. 83: с. 47–51.
- 28. Чжан М.-Л. и Чжоу З.-Х., ML-KNN: ленивый подход к обучению с несколькими ярлыками. Распознавание образов, 2007.40 (7): с. 2038–2048.
- 29. Дханабал С. и Чандрамати С. Обзор различных методов обработки запросов k-ближайшего соседа. Международный журнал компьютерных приложений, 2011. 31 (7): с. 14–22.
- 30. Оуян К., Чжао Дж. И Чен К. Классификация рисового вина по разным отмеченным возрастам с использованием портативного многоэлектродного электронного языка в сочетании с многомерным анализом. Food Research International, 2013. 51 (2): p. 633–640.
- 31.Ivorra E. и др., Прогнозирование срока годности охлажденного копченого лосося в вакуумной упаковке с истекшим сроком годности на основе метода сегментации ткани KNN с использованием гиперспектральных изображений. Журнал пищевой инженерии, 2016. 178: с. 110–116.
- 32. Макелеле Л. и др., Микробиологическое качество продуктов питания, продаваемых уличными торговцами в Кисангани, Демократическая Республика Конго. Африканский журнал пищевой науки, 2015. 9 (5): стр. 285–290.
- 33. Сулиман А. и Чжан Ю. Обзор нейронных сетей обратного распространения в применении классификации изображений дистанционного зондирования.Журнал наук о Земле и инженерии, 2015. 5: с. 52–65.
- 34. Магваза Л.С. и др., Применение спектроскопии в ближнем ИК-диапазоне для внутреннего и внешнего анализа качества цитрусовых — обзор. Food and Bioprocess Technology, 2012. 5 (2): с. 425–444.
- 35. Чжоу Ю., Ю. Ван и К. Яо. Сегментация пятен болезней риса на основе улучшенного BPNN. в 2010 г. Международная конференция по анализу изображений и обработке сигналов. 2010. IEEE.
- 36. Лю Д.и др., Различение разновидностей личи с помощью гиперспектральной визуализации в сочетании с многомерной классификацией. Методы анализа пищевых продуктов, 2014. 7 (9): с. 1848–1857 гг.
- 37. Лоренцо-Сева У., Как указать процент объясненной общей дисперсии в исследовательском факторном анализе. Таррагона, Италия: Департамент психологии, 2013.
- 38. Лин С.-В. и др., Оптимизация роя частиц для определения параметров и выбора характеристик машин опорных векторов. Экспертные системы с приложениями, 2008.35 (4): с. 1817–1824 гг.
- 39. Козьма Л., k Алгоритм ближайших соседей (kNN). Хельсинкский технологический университет, 2008 г.
- 40. Дай Х. и Макбет К. Влияние параметров обучения на процедуру обучения и производительность BPNN. Нейронные сети, 1997. 10 (8): с. 1505–1521. pmid: 12662490
- 41. Розенталь Р. и Рубин Д. Б., Заметка о процентной дисперсии, объясненной как мера важности эффектов. Журнал прикладной социальной психологии, 1979.9 (5): с. 395–396.
Определение ядовитых грибов по правилам классификации
Часть 1: Сбор данных —————–
Набор данных грибов доступен в репозитории машинного обучения UCI (http://archive.ics.uci.edu/ml). Набор данных грибов будет использоваться для классификации с использованием разных правил. Правила основаны на методе «отделяй и властвуй», который позволяет жадно добавлять правила до тех пор, пока не будет полностью классифицирована часть данных или пока не закончатся возможности для разделения.
Часть 2: Ученики правил ——————-
Всего в наборе данных 8124 наблюдений (строк) грибов и 23 объекта (столбцы). Для stringAsFactors на этот раз установлено значение true, потому что все функции являются номинальными и будут подходить для изучающих правила классификации в этом упражнении.
setwd ("C: / Users / Emily / Desktop / КУРСЫ ВЫПУСКНОЙ ПРОГРАММЫ / STAT6620 Машинное обучение с R / Машинное обучение с R, второе издание_код / глава 05")
грибы <- прочтите.csv ("грибы.csv", stringsAsFactors = ИСТИНА)
ул (грибы) ## 'data.frame': 8124 obs. из 23 переменных:
## $ type: Фактор с 2 уровнями «съедобный», «ядовитый»: 2 1 1 2 1 1 1 1 2 1 ...
## $ cap_shape: Фактор с 6 уровнями "раструб", "конус", ..: 3 3 1 3 3 3 1 1 3 1 ...
## $ cap_surface: Фактор с 4 уровнями «волокнистый», «бороздки», ..: 4 4 4 3 4 3 4 3 3 4 ...
## $ cap_color: Фактор с 10 уровнями «коричневый», «бафф» ,..: 1 10 9 9 4 10 9 9 9 10 ...
## $ bruises: множитель с двумя уровнями «нет», «да»: 2 2 2 2 1 2 2 2 2 2 ...
## $ запах: Фактор с 9 уровнями «миндаль», «анис», ..: 8 1 2 8 7 1 1 2 8 1 ...
## $ gill_attachment: Фактор с 2 уровнями "прикреплен", "бесплатно": 2 2 2 2 2 2 2 2 2 2 ...
## $ gill_spacing: Фактор с 2 уровнями "закрыто", "переполнено": 1 1 1 1 2 1 1 1 1 1 ...
## $ gill_size: Фактор с 2 уровнями «широкий», «узкий»: 2 1 1 2 1 1 1 1 2 1...
## $ gill_color: Фактор с 12 уровнями "черный", "коричневый", ..: 1 1 2 2 1 2 5 2 8 5 ...
## $ stalk_shape: Фактор с 2 уровнями "увеличения", "сужения": 1 1 1 1 2 1 1 1 1 1 ...
## $ stalk_root: Фактор с 5 уровнями "выпуклый", "клубный", ..: 3 2 2 3 3 2 2 2 3 2 ...
## $ stalk_surface_above_ring: Фактор с 4 уровнями «волокнистый», «чешуйчатый», ..: 4 4 4 4 4 4 4 4 4 4 ...
## $ stalk_surface_below_ring: Фактор с 4 уровнями «волокнистый», «чешуйчатый», ..: 4 4 4 4 4 4 4 4 4 4...
## $ stalk_color_above_ring: Фактор с 9 уровнями «коричневый», «бафф», ..: 8 8 8 8 8 8 8 8 8 8 ...
## $ stalk_color_below_ring: Фактор с 9 уровнями «коричневый», «бафф», ..: 8 8 8 8 8 8 8 8 8 8 ...
## $ veil_type: Фактор с 1 уровнем "частичный": 1 1 1 1 1 1 1 1 1 1 ...
## $ veil_color: Коэффициент с 4 уровнями "коричневый", "оранжевый", ..: 3 3 3 3 3 3 3 3 3 3 ...
## $ ring_number: множитель с 3 уровнями «нет», «один», «два»: 2 2 2 2 2 2 2 2 2 2 ...
## $ ring_type: Фактор с 5 уровнями "непродолжительный", "вспыхивающий"..: 5 5 5 5 1 5 5 5 5 5 ...
## $ spore_print_color: Коэффициент с 9 уровнями «черный», «коричневый», ..: 1 2 2 1 2 1 1 2 1 1 ...
## $ Population: Фактор с 6 уровнями "изобилие", "кластеризация", ..: 4 3 3 4 1 3 3 4 5 4 ...
## $ среда обитания: Фактор с 7 уровнями «трава», «листья», ..: 5 1 3 5 1 1 3 3 1 3 ... Номинальные характеристики, которые содержат несколько различных категорий для каждого объекта, могут быть полезны при классификации позже, поскольку новый тип класса наблюдения может быть предсказан на основе аналогичного уровня класса объекта.Однако в наборе данных есть одна функция, которая содержит только один уровень, функция veil_type, которая бесполезна для целей классификации, поскольку при дифференциации классов на основе одного и того же значения уровня фактора получается не слишком много информации. Следовательно, перед переходом к следующему шагу эта функция удаляется.
грибов $ veil_type <- NULL
ул (грибы) ## 'data.frame': 8124 obs. из 22 переменных:
## $ type: Фактор с 2 уровнями «съедобный», «ядовитый»: 2 1 1 2 1 1 1 1 2 1...
## $ cap_shape: Фактор с 6 уровнями "раструб", "конус", ..: 3 3 1 3 3 3 1 1 3 1 ...
## $ cap_surface: Фактор с 4 уровнями «волокнистый», «бороздки», ..: 4 4 4 3 4 3 4 3 3 4 ...
## $ cap_color: Фактор с 10 уровнями "коричневый", "желтый", ..: 1 10 9 9 4 10 9 9 9 10 ...
## $ bruises: множитель с двумя уровнями «нет», «да»: 2 2 2 2 1 2 2 2 2 2 ...
## $ запах: Фактор с 9 уровнями «миндаля», «аниса», ..: 8 1 2 8 7 1 1 2 8 1...
## $ gill_attachment: Фактор с 2 уровнями "прикреплен", "бесплатно": 2 2 2 2 2 2 2 2 2 2 ...
## $ gill_spacing: Фактор с 2 уровнями "закрыто", "переполнено": 1 1 1 1 2 1 1 1 1 1 ...
## $ gill_size: Фактор с 2 уровнями «широкий», «узкий»: 2 1 1 2 1 1 1 1 2 1 ...
## $ gill_color: Фактор с 12 уровнями "черный", "коричневый", ..: 1 1 2 2 1 2 5 2 8 5 ...
## $ stalk_shape: Фактор с 2 уровнями "увеличения", "сужения": 1 1 1 1 2 1 1 1 1 1...
## $ stalk_root: Фактор с 5 уровнями "выпуклый", "клубный", ..: 3 2 2 3 3 2 2 2 3 2 ...
## $ stalk_surface_above_ring: Фактор с 4 уровнями «волокнистый», «чешуйчатый», ..: 4 4 4 4 4 4 4 4 4 4 ...
## $ stalk_surface_below_ring: Фактор с 4 уровнями "волокнистый", "чешуйчатый", ..: 4 4 4 4 4 4 4 4 4 4 ...
## $ stalk_color_above_ring: Фактор с 9 уровнями «коричневый», «бафф», ..: 8 8 8 8 8 8 8 8 8 8 ...
## $ stalk_color_below_ring: Фактор с 9 уровнями «коричневый», «бафф», ..: 8 8 8 8 8 8 8 8 8 8...
## $ veil_color: Коэффициент с 4 уровнями "коричневый", "оранжевый", ..: 3 3 3 3 3 3 3 3 3 3 ...
## $ ring_number: множитель с 3 уровнями «нет», «один», «два»: 2 2 2 2 2 2 2 2 2 2 ...
## $ ring_type: Фактор с 5 уровнями "непродолжительный", "вспыхивающий", ..: 5 5 5 5 1 5 5 5 5 5 ...
## $ spore_print_color: Коэффициент с 9 уровнями «черный», «коричневый», ..: 1 2 2 1 2 1 1 2 1 1 ...
## $ Population: Фактор с 6 уровнями «изобилие», «кластеризация», ..: 4 3 3 4 1 3 3 4 5 4...
## $ среда обитания: Фактор с 7 уровнями «трава», «листья», ..: 5 1 3 5 1 1 3 3 1 3 ... Использование функции table () для понимания доли грибовидного типа целевой метки в наборе данных. Есть 4208 съедобных и 3916 ядовитых грибов.
стол (грибы $ типа) ##
## съедобный ядовитый
## 4208 3916 7000 наблюдений были случайным образом выбраны в качестве обученного набора данных, а оставшиеся 1124 наблюдения были проверены как набор данных.
набор. Семян (123)
train_sample <- образец (8124, 7000)
str (train_sample) ## int [1: 7000] 2337 6404 3322 7171 7637 370 4288 7244 4476 3706 ... гриб_поезд <- грибы [train_sample,]
Грибы_тест <- грибы [-train_sample,] Для алгоритма обучения правилам классификации загружен пакетRweka.
библиотека (RWeka) ## Предупреждение: пакет 'RWeka' был собран под R версии 3.3,3 Шаг 3. Обучение модели на данных -
Использование функции OneR (), чтобы взять все 21 функцию в качестве предикторов для прогнозирования типа грибов (съедобные / ядовитые) в обученном наборе данных по грибам.
Чтобы изучить алгоритм правил OneR (), введите имя объекта классификатора. Алгоритм правил OneR () показывает, что на основе сравнения частоты ошибок каждого 21 признака, признак запаха, содержащий минимальную частоту ошибок, был выбран для основной классификации типа гриба.Каждая категория признака запаха была классифицирована как съедобная или ядовитая на основании большинства голосов каждой категории.
гриб_1R <- OneR (тип ~., Данные = гриб_поезд)
гриб_1R ## запах:
## миндаль -> съедобный
## анис -> съедобный
## креозот -> ядовитый
## рыбный -> ядовитый
## фол -> ядовитый
## затхлый -> ядовитый
## none -> съедобный
## острый -> ядовитый
## острый -> ядовитый
## (правильно 6895/7000 экземпляров) Использование функции summary () для детального изучения алгоритма классификатора правил OneR ().Из 7000 наблюдений в обученном наборе данных есть 105 наблюдений за грибами, которые неправильно классифицируются, что недопустимо, поскольку вероятность ошибки 1,5% может привести к большой части людей, которые заболеют или даже погибнут.
Внизу сводки находится матрица путаницы модели OneR, 105 инцидентов были ошибочно классифицированы как съедобные, хотя на самом деле они были ядовитыми. Это приводит к общей точности 98,5% и ошибке 1,5%.
сводка (гриб_1R) ##
## === Резюме ===
##
## Правильно классифицированные экземпляры 6895 98.5%
## Неправильно классифицированные экземпляры 105 1,5%
## Статистика Каппа 0,9699
## Средняя абсолютная ошибка 0,015
## Среднеквадратичная ошибка 0,1225
## Относительная абсолютная погрешность 3,0039%
## Относительная квадратная ошибка корня 24,5 · 108%
## Общее количество экземпляров 7000
##
## === Матрица неточностей ===
##
## a b <- классифицируется как
## 3626 0 | а = съедобный
## 105 3269 | б = ядовитый Шаг 4. Оценка производительности модели -
Модель классификатора OneR используется для прогнозирования типа грибов в тестируемом наборе данных.Загрузив пакет gmodels, мы можем использовать функцию CroosTable (), чтобы создать матрицу путаницы для тестируемого набора данных.
Из 1124 общих наблюдений за грибами в протестированном наборе данных 15 инцидентов были ошибочно классифицированы как съедобные, хотя на самом деле они были ядовитыми. Это общая точность 98,6% и ошибка 1,3%.
гриб_пред <- прогнозировать (гриб_1R, гриб_тест)
библиотека (gmodels) ## Предупреждение: пакет 'gmodels' был собран под R версии 3.3,3 CrossTable (гриб_тест $ тип, гриб_пред,
prop.chisq = FALSE, prop.c = FALSE, prop.r = FALSE,
dnn = c ('фактическое значение по умолчанию', 'прогнозируемое значение по умолчанию')) ##
##
## Содержимое ячейки
## | ------------------------- |
## | N |
## | N / Таблица Итого |
## | ------------------------- |
##
##
## Всего наблюдений в таблице: 1124
##
##
## | прогнозируемый дефолт
## фактическое значение по умолчанию | съедобный | ядовитый | Итого по строке |
## --------------- | ----------- | ----------- | -------- --- |
## съедобное | 582 | 0 | 582 |
## | 0.518 | 0,000 | |
## --------------- | ----------- | ----------- | -------- --- |
## ядовитый | 15 | 527 | 542 |
## | 0,013 | 0,469 | |
## --------------- | ----------- | ----------- | -------- --- |
## Итого по столбцу | 597 | 527 | 1124 |
## --------------- | ----------- | ----------- | -------- --- |
##
## Шаг 5. Повышение производительности модели -
Ставить человеческие жизни только на одну особенность (характеристики) гриба для определения его типа слишком рискованно.Более сложная модель - это повторяющееся инкрементное сокращение для уменьшения количества ошибок (RIPPER), которое может использовать не только одно, но и набор правил логическим образом if-else для определения типа для каждого наблюдения. Он создает гораздо более сложные правила, чем алгоритм OneR, поскольку он учитывает несколько функций.
Функция RRip () будет использоваться для алгоритма правил RIPPER. Поскольку и OneR (), и JRip () находятся в пакете Rweka, их синтаксис очень похож и удобен для сравнения моделей.
На основе того же набора данных алгоритм RIPPER использовал в общей сложности девять правил вместо одного в OneR для классификации типов грибов. Предыдущие восемь правил специально идентифицируют ядовитые грибы по количеству встречаемости в скобках, и оставляют последнее правило, чтобы сказать, что все остальное, не перечисленное в предыдущих восьми правилах, классифицируется как «съедобное».
Используя набор правил для создания гораздо более сложных вычислений, матрица неточностей модели RIPPER показывает 100% точность и 0% ошибку! Большое улучшение по сравнению с алгоритмом OneR.Это идеально подходит для классификации грибов по типу, поскольку мы не можем рисковать жизнями из-за того, что проглотили не тот тип грибов.
Mushroom_JRip <- JRip (тип ~., Data = Mushrooms_train)
гриб_JRip ## Правила JRIP:
## ===========
##
## (запах = неприятный запах) => тип = ядовитый (1860.0 / 0.0)
## (gill_size = узкий) и (gill_color = buff) => тип = ядовитый (986.0 / 0.0)
## (gill_size = узкий) и (запах = острый) => тип = ядовитый (222.0 / 0,0)
## (запах = креозот) => тип = ядовитый (171,0 / 0,0)
## (spore_print_color = green) => тип = ядовитый (65,0 / 0,0)
## (stalk_surface_below_ring = чешуйчатый) и (stalk_surface_above_ring = шелковистый) => тип = ядовитый (58.0 / 0.0)
## (среда обитания = листья) и (cap_surface = чешуйчатая) и (популяция = кластеризованная) => тип = ядовитая (10,0 / 0,0)
## (cap_surface = grooves) => тип = ядовитый (2.0 / 0.0)
## => type = съедобный (3626,0 / 0,0)
##
## Количество правил: 9 сводка (гриб_JRip) ##
## === Резюме ===
##
## Правильно классифицированные экземпляры 7000 100%
## Неверно классифицированные экземпляры 0 0%
## Статистика Каппа 1
## Средняя абсолютная ошибка 0
## Среднеквадратичная ошибка 0
## Относительная абсолютная погрешность 0%
## Относительная квадратная ошибка корня 0%
## Общее количество экземпляров 7000
##
## === Матрица неточностей ===
##
## a b <- классифицируется как
## 3626 0 | а = съедобный
## 0 3374 | б = ядовитый Прогноз типов грибов производится с использованием модели RIPPER на протестированном наборе данных.Матрица неточностей показывает 100% точность и 0% ошибку для всех наблюдений в протестированном наборе данных.
гриб_пред <- прогнозировать (гриб_JRip, гриб_тест)
библиотека (модели)
CrossTable (гриб_тест $ тип, гриб_пред,
prop.chisq = FALSE, prop.c = FALSE, prop.r = FALSE,
dnn = c ('фактическое значение по умолчанию', 'прогнозируемое значение по умолчанию')) ##
##
## Содержимое ячейки
## | ------------------------- |
## | N |
## | N / Таблица Итого |
## | ------------------------- |
##
##
## Всего наблюдений в таблице: 1124
##
##
## | прогнозируемый дефолт
## фактическое значение по умолчанию | съедобный | ядовитый | Итого по строке |
## --------------- | ----------- | ----------- | -------- --- |
## съедобное | 582 | 0 | 582 |
## | 0.518 | 0,000 | |
## --------------- | ----------- | ----------- | -------- --- |
## ядовитый | 0 | 542 | 542 |
## | 0,000 | 0,482 | |
## --------------- | ----------- | ----------- | -------- --- |
## Итого по столбцу | 582 | 542 | 1124 |
## --------------- | ----------- | ----------- | -------- --- |
##
## Примечание: что делать, если использовать алгоритм Decision Tress? —-
Модель C5.0 был использован в пакете C50 для набора данных грибов просто для сравнения с классификацией на основе правил для развлечения. Было выбрано только два признака / предиктора для модели прядей решения. Матрица неточностей модели показывает, что 105 инцидентов были ошибочно классифицированы как съедобные, хотя на самом деле они являются ядовитыми, что дает точность 98,5% и ошибку 1,5%. Результат очень похож на ученика алгоритма OneR на основе правил.
библиотека (C50) ## Предупреждение: пакет «C50» был собран под R версии 3.3,3 Mushroom_c5rules <- C5.0 (тип ~ запах + размер жабр,
data = Mushrooms_train, rules = ИСТИНА)
Mushroom_c5rules ##
## Вызов:
## C5.0.formula (formula = type ~ odor + gill_size, data =
## Mushrooms_train, rules = ИСТИНА)
##
## Модель на основе правил
## Количество образцов: 7000
## Количество предикторов: 2
##
## Количество правил: 2
##
## Нестандартные варианты: попытаться сгруппировать атрибуты сводка (Mushroom_c5rules) ##
## Вызов:
## C5.0. формула (формула = тип ~ запах + размер жабры, данные =
## Mushrooms_train, rules = ИСТИНА)
##
##
## C5.0 [Выпуск 2.07 GPL Edition] Пн, 01 мая, 00:13:15, 2017 г.
## -------------------------------
##
## Класс, указанный атрибутом `результат '
##
## Прочитать 7000 случаев (3 атрибута) из undefined.data
##
## Правила:
##
## Правило 1: (3731/105, подъем 1,9)
## запах в {миндале, анисе, без запаха}
## -> класс съедобный [0,972]
##
## Правило 2: (3269, лифт 2.1)
## запах в {креозоте, рыбном, неприятном, плесневом, остром, пряном}
## -> класс ядовитый [1.000]
##
## Класс по умолчанию: съедобный
##
##
## Оценка данных обучения (7000 случаев):
##
## Правила
## ----------------
## Нет ошибок
##
## 2 105 (1,5%) <<
##
##
## (a) (b) <-классифицируется как
## ---- ----
## 3626 (a): сорт съедобный
## 105 3269 (b): класс ядовитый
##
##
## Использование атрибута:
##
## 100.00% запах
##
##
## Время: 0,0 с Используя модель дерева решений на протестированном наборе данных грибов, создается прогноз для типа грибов, который сравнивается с фактической меткой класса. Матрица неточностей показывает 15 случаев ошибочной классификации в съедобные (ложноотрицательные), что опять же аналогично результату использования алгоритма OneR.
Mushroom_pred <- прогнозировать (Mushroom_c5rules, Mushrooms_test)
библиотека (модели)
CrossTable (гриб_тест $ тип, гриб_пред,
опораchisq = FALSE, prop.c = FALSE, prop.r = FALSE,
dnn = c ('фактическое значение по умолчанию', 'прогнозируемое значение по умолчанию')) ##
##
## Содержимое ячейки
## | ------------------------- |
## | N |
## | N / Таблица Итого |
## | ------------------------- |
##
##
## Всего наблюдений в таблице: 1124
##
##
## | прогнозируемый дефолт
## фактическое значение по умолчанию | съедобный | ядовитый | Итого по строке |
## --------------- | ----------- | ----------- | -------- --- |
## съедобное | 582 | 0 | 582 |
## | 0.518 | 0,000 | |
## --------------- | ----------- | ----------- | -------- --- |
## ядовитый | 15 | 527 | 542 |
## | 0,013 | 0,469 | |
## --------------- | ----------- | ----------- | -------- --- |
## Итого по столбцу | 597 | 527 | 1124 |
## --------------- | ----------- | ----------- | -------- --- |
##
## Заключение: И One R, и RIPPER представляют собой алгоритмы классификации, основанные на правилах, и они используют методы «разделяй и властвуй», чтобы жадно добавлять правила, пока не классифицируется подмножество данных или пока не закончатся функции для разделения.И R, и RIPPER хороши для классификации по номинальному результату на основе номинальных предикторов, тогда как прядь решения может использоваться как для числовых, так и для номинальных предикторов / признаков. Кроме того, алгоритм, основанный на изучении правил, может повторно исследовать случаи, которые были рассмотрены, но не были охвачены предыдущими правилами, поэтому они считаются более экономными по сравнению с деревом решений, которое не может повторно исследовать или изменять существующие разделы. В целом алгоритм классификации правил RIPPER может обрабатывать более сложные данные и генерировать несколько правил в конце, что может привести к более высокой точности прогнозирования классификации.
Классификация грибов в случайном лесу - Stoltzman Consulting
Существует множество алгоритмов классификации, доступных людям, имеющим некоторый опыт программирования и набор данных. Распространенным методом машинного обучения является случайный лес, который является хорошим местом для начала. Это вариант использования в R пакета randomForest , используемого для набора данных из репозитория данных машинного обучения UCI.
Съедобны ли эти грибы?
Если бы кто-то дал вам тысячи строк данных с десятками столбцов о грибах, могли бы вы определить, какие характеристики делают гриб съедобным или ядовитым? Насколько вы бы доверяли своей модели? Достаточно ли вам принять решение, есть ли найденный вами гриб? (Это плохое решение примерно в 100% случаев).Пакет randomForest выполняет всю тяжелую работу за кулисами. Хотя это «волшебство» невероятно приятно для конечного пользователя, важно понимать, что вы делаете. Имейте это в виду для абсолютно любого пакета, который вы используете на R или любом другом языке.
«Знание того, как запускать эти программы, впечатляет, но истинное понимание того, как и почему они работают, делает вас экспертом!» -Хейли Штольцман (моя жена гений)
Вот статья, которая объясняет вещи в условиях непрофессионала - Нежное введение в случайные леса, ансамбли и показатели производительности в коммерческой системе.Я создал функцию для сбора и очистки данных. Это был очень ручной процесс, поэтому я позаимствовал много кода у других. Позже я обнаружил, что набор данных уже был очищен кем-то другим и представлен в виде файла .csv, но я все равно решил использовать свою функцию.
источник ('helper_functions.R') библиотека (randomForest) библиотека (e1071) библиотека (каретка) библиотека (ggplot2) set.seed (123) Я ввел данные в виде фрейма данных, первый столбец - «Съедобный», который можно обозначить как «Класс», так как это то, что мы ищем в классификации.Здесь мы найдем только два значения: «Съедобный» и «Ядовитый» (имейте в виду, что более двух значений легко обрабатываются случайным лесом). Я распечатал первые несколько строк, и результат показывает нам 23 столбца (включая «Съедобный»). Я не специалист по грибам, но большую часть этих данных имеет смысл попробовать и использовать.
# Импорт данных через пользовательскую функцию data = fetchAndCleanData () head (data) ## съедобный CapShape CapSurface CapColor Синяки Запах GillAttachment ## 1 Ядовитый выпуклый гладкий коричневый истинный острый запах ## 2 съедобный выпуклый гладкий желтый истинный миндаль без ## 3 съедобный колокольчик гладкий белый без истинного аниса ## 4 Ядовитый выпуклый чешуйчатый белый истинный острый запах Free ## 5 Съедобный выпуклый гладкий серый False None Free ## 6 Съедобный выпуклый чешуйчатый желтый Настоящий миндаль Без ## GillSpacing GillSize GillColor StalkShape StalkRoot ## 1 Закрыть Узкий черный Увеличивающийся Равный ## 2 Закрыть Широкий черный Увеличивающийся клуб ## 3 Закрыть Широкий коричневый Увеличивающаяся булава ## 4 Закрыть узкая коричневая увеличивающаяся равная ## 5 Толстая широкая черная сужающаяся равная ## 6 Закрытая широкая коричневая расширяющаяся булавка ## СтебельПоверхностьВверху Кольцо СтебельПоверхностьПоверхностьНижнее кольцо СтебельЦвет Над кольцом ## 1 Smooth Smooth White ## 2 Smooth Smooth White ## 3 Smooth Smooth White ## 4 Smooth Smooth White ## 5 Smooth Smooth White ## 6 Smooth Smooth White ## StalkColorBelowRing VeilType VeilColor RingNumber RingType ## 1 White Partial White One Pendant ## 2 Белый Частично Белый Один Кулон ## 3 Белый Частичный Белый Один Кулон ## 4 Белый Частичный Белый Один Кулон ## 5 Белый Частичный Белый Один Evanescent ## 6 Белый Частичный Белый Один Кулон ## SporePrintColor Population Habitat ## 1 Черный Разрозненный Город # # 2 Коричневые многочисленные травы ## 3 Коричневые нумеро us Meadows ## 4 Черные рассеянные городские ## 5 Коричневые изобильные травы ## 6 Черные многочисленные травы Важно знать, что пакет случайного леса R не может использовать строки с отсутствующими данными.Использование функции summary () может помочь в выявлении проблем. В этих данных нет недостающей информации.
сводка (данные) # отсутствуют недостающие данные ## Съедобный CapShape CapSurface CapColor ## Съедобный: 4208 Выпуклый: 3656 Чешуйчатый: 3244 Коричневый: 2284 ## Ядовитый: 3916 Плоский: 3152 Гладкий: 2556 Серый: 1840 ## Ручка: 828 Волокнистый: 2320 Красный: 1500 ## Колокол : 452 Канавки: 4 Желтый: 1072 ## Затонувший: 32 f: 0 Белый: 1040 ## Конический: 4 г: 0 Бафф: 168 ## (Другой): 0 (Другой): 0 (Другой): 220 ## Ушибы Запах GillAttachment GillSpacing ## f: 0 Нет: 3528 a: 0 c: 0 ## t: 0 Фол: 2160 f: 0 w: 0 ## Верно: 3376 Рыбный: 576 Прикреплено: 210 Закрыто: 6812 ## Ложь: 4748 Пряный: 576 По убыванию: 0 Насыщенный: 1312 ## Миндальный: 400 Свободный: 7914 Отдаленный: 0 ## Анис: 400 Зубчатый: 0 ## (Другое): 484 ## GillSize GillColor StalkShape StalkRoot ## b: 0 Buff: 1728 e: 0 Луковичный: 3776 ## n: 0 Розовый: 1492 t: 0 Отсутствует: 2480 ## Широкий: 5612 Белый: 1202 Увеличение: 3516 Равно: 1120 ## Узкий: 2512 Коричневый : 1048 Сужение: 4608 Клуб: 556 ## Серый: 752 Корневой: 192 ## Шоколадный: 732? : 0 ## (Other): 1170 (Other): 0 ## StalkSurfaceAboveRing StalkSurfaceBelowRing StalkColorAboveRing ## Smooth: 5176 Smooth: 4936 White: 4464 ## Silky: 2372 Silky: 2304 Pink: 1872 ## Fibrous: 552 Fibrous: 600 Gray : 576 ## Чешуйчатый: 24 Чешуйчатый: 284 Коричневый: 448 ## f: 0 f: 0 Бафф: 432 ## k: 0 k: 0 Оранжевый: 192 ## (Другой): 0 (Другой): 0 (Другой) : 140 ## StalkColorBelowRing VeilType VeilColor RingNumber ## Белый: 4384 p: 0 Белый: 7924 n: 0 ## Розовый: 1872 Частично: 8124 Коричневый: 96 o: 0 ## Серый: 576 Универсальный: 0 Оранжевый: 96 t: 0 ## Коричневый: 512 Желтый: 8 Нет: 36 ## Бафф: 432 n: 0 Один: 7488 ## Оранжевый: 192 o: 0 Два: 600 ## (Другое): 156 (Другое): 0 ## RingType SporePrintColor Population Habitat ## Подвеска: 3968 Белый: 2388 Несколько: 4040 Лес: 3148 ## Evanescent: 2776 Коричневый: 1968 Одиночный: 1712 Травы: 2148 # # Большой: 1296 Черный: 1872 Разброс: 1248 Пути: 1144 ## Расклешенный: 48 Шоколадный: 1632 Много: 400 Листьев: 832 ## Нет: 36 Зеленый: 72 Обильный: 384 Городской: 368 ## e: 0 Бафф: 48 Кластерный : 340 Луга: 292 ## (Другой): 0 (Другой): 144 (Другой): 0 (Другой): 192 Я хочу изучить данные, прежде чем подбирать модель, чтобы понять, чего ожидать.Я рисую переменную по двум осям и использую цвета, чтобы увидеть взаимосвязь между съедобными или ядовитыми грибами. На этих графиках съедобные обозначены зеленым цветом, а ядовитые - красным. Я ищу места, где существует подавляющее большинство одного цвета. Сравнение CapSurface с CapShape показывает:
- CapShape Bell более съедобен
- CapShape Convex или Flat содержат смесь съедобного и ядовитого и составляют большую часть данных
- CapSurface сам по себе не дает нам много информации
- CapSurface Fibrous + CapShape Bell, Knobbed или Sunken могут быть съедобными
- Эти переменные, вероятно, увеличат прирост информации , но не могут быть невероятно сильными
p = ggplot (data, aes (x = CapShape, y = CapSurface, color = Edible)) p + geom_jitter (alpha = 0.3) + scale_color_manual (breaks = c ('Съедобный', 'Ядовитый'), values = c ('темно-зеленый', 'красный')) Сравнение «StalkColorBelowRing» со «StalkColorAboveRing» показывает нам:
- StalkColorAboveRing Grey почти всегда будет съедобным
- StalkColorBelowRing Gray почти всегда будет съедобным
- StalkColorBelowRing Buff почти всегда будет ядовитым
- Этот список можно продолжать ...
- Эти переменные, вероятно, увеличат прирост информации на справедливую сумму
p = ggplot (data, aes (x = StalkColorBelowRing, y = StalkColorAboveRing, color = Edible)) p + geom_jitter (alpha = 0.3) + scale_color_manual (breaks = c ('Съедобный', 'Ядовитый'), values = c ('темно-зеленый', 'красный')) Сравнение «Запах» и «SporePrintColor» показывает нам:
- Неприятный запах, рыбный, острый, креозотовый и пряный с большой вероятностью ядовитый
- Запах Миндаль и анис, скорее всего, съедобны.
- Запах Нет, похоже, в основном съедобный
- Однако, если он имеет SporePrintColor Green, он, скорее всего, будет ядовитым!
- Эти переменные, вероятно, приведут к большому увеличению количества информации
p = ggplot (data, aes (x = Odor, y = SporePrintColor, color = Edible)) p + geom_jitter (alpha = 0.3) + scale_color_manual (breaks = c ('Съедобный', 'Ядовитый'), values = c ('темно-зеленый', 'красный')) Из-за того, насколько сильными выглядели эти переменные, я решил обозначить их строго как съедобные или ядовитые и обнаружил:
- Запах - отличный индикатор съедобного или ядовитого
- Запах Нет - единственный неприятный запах - есть данные, по которым он был бы классифицирован как съедобный или ядовитый
- SporePrintColor не так сильно, как запах, когда он стоит отдельно - между столбцами много перекрытий
p = ggplot (data, aes (x = съедобный, y = запах, цвет = съедобный)) p + geom_jitter (alpha = 0.2) + scale_color_manual (breaks = c ('Съедобный', 'Ядовитый'), values = c ('темно-зеленый', 'красный')) p = ggplot (data, aes (x = Edible, y = SporePrintColor, color = Edible)) p + geom_jitter (alpha = 0,2) + scale_color_manual (breaks = c ('Съедобный', 'Ядовитый'), values = c ('темно-зеленый', 'красный')) Перед подгонкой модели важно разделить данные на разные части - данные обучения и тестирования. Не существует идеального способа точно узнать, сколько данных вам следует использовать для обучения вашей модели. В этом примере я разделил 5% на обучение и 95% на тестирование.Однако это не типично, большая часть того, что я вижу, обычно составляет около 60% / 40% или 70% / 30% для разделения теста / обучения. Если вы выберете слишком большой обучающий набор, вы рискуете переобучиться своей модели. Переобучение - это классическая ошибка, которую делают люди, впервые попадая в сферу машинного обучения. Я не буду вдаваться в подробности, но есть классы, посвященные этой теме. Статья в Википедии Изначально я запускал это на более высоких уровнях обучающих данных, и у него было совершенное предсказание без ложных срабатываний или отрицаний.Это не так интересно рассматривать в качестве примера, поэтому я уменьшил тренировочные данные, что привело к более плохим прогнозам.
# Создать данные для trainingsample.ind = sample (2, nrow (data), replace = T, prob = c (0.05,0.95)) data.dev = data [sample.ind == 1,] data.val = данные [sample.ind == 2,] Я хотел узнать разделение съедобных грибов на ядовитые в наборе данных и сравнить его с данными обучения и тестирования. Случайная выборка, по-видимому, создала примерно такое же соотношение съедобного и ядовитого при создании поездов и тестовых данных.Съедобный% / Ядовитый%:
- Данные: 52/48
- Поезд: 50/50
- Тест: 52/48
# Original Datatable (data $ Edible) / nrow (data) ## Edible Poisonous ## 0,5179714 0,4820286 # Training Datatable (data.dev $ Edible) / nrow (data.dev) ## Edible Poisonous ## 0,4962779 0,5037221 # Testing Datatable (data.val $ Edible) / nrow (data.val) ## Edible Poisonous ## 0.51 0.4808963 Я наконец подобрал модель случайного леса к обучающим данным.Построение модели показывает, что примерно после 20 деревьев ошибка не сильно меняется. Он немного колеблется, но не в большой степени.
#Fit Random Forest Modelrf = randomForest (Edible ~., Ntree = 100, data = data.dev) plot (rf) Распечатка модели показывает, что количество переменных, опробованных на каждом разбиении, равно 4, а оценка коэффициента ошибок при внеплановой работе составляет 0,25%. Модель обучения почти идеально соответствовала обучающим данным. Был только один гриб, классифицированный неправильно.Модель предсказывала бы, что 1 ядовит, и он оказался бы съедобным. Если мы считаем съедобный «положительным», это означает, что у нас был бы 1 ложноотрицательный результат.
print (rf) ## Call: ## randomForest (formula = Edible ~., Data = data.dev, ntree = 100) ## Тип случайного леса: классификация ## Количество деревьев: 100 ## No. количества переменных, опробованных при каждом разбиении: 4 #### Оценка OOB для частоты ошибок: 0,25% ## Матрица ошибок: ## Съедобный ядовитый класс.ошибка ## Съедобный 200 0 0,000000000 ## Ядовитый 1202 0,004926108 Всегда важно смотреть на то, что показано с точки зрения важности переменных. Этот график показывает, какие переменные оказали наибольшее влияние на модель классификации. Я ограничил его до 10 для графика.
# Важность переменной varImpPlot (rf, sort = T, n.var = 10, main = "10 первых - важность переменной") Запах - безусловно, самая важная переменная с точки зрения «среднего убывающего Джини» - аналогичный термин для прироста информации в этом примере.Остальные результаты перечислены ниже. Интересно отметить, что «Veil Type» не привносит никакой информации - поэтому я посмотрел на него в исходных данных. Причина ясна - существует только один VeilType, поэтому он не предлагает никакой дифференциации и не может повлиять на результаты.
#Variable Importancevar.imp = data.frame (important (rf, type = 2)) # сделать имена строк как columnsvar.imp $ Variables = row.names (var.imp) print (var.imp [order (var .imp $ MeanDecreaseGini, уменьшение = T),]) ## Переменные MeanDecreaseGini ## Запах 69.3536782 Запах ## SporePrintColor 27.3837625 SporePrintColor ## GillColor 18.1981987 GillColor ## StalkSurfaceAboveRing 12.3172400 StalkSurfaceAboveRing ## RingType 11.3114967 RingType## Bruises ## Bruises2Size ## 7,29471 GillSize ## 7,256746095 CapColor ## Место обитания 5.4768013 обитания ## StalkRoot 5.3053036 StalkRoot ## StalkSurfaceBelowRing 4.6080070 StalkSurfaceBelowRing ## GillSpacing 4.1186021 GillSpacing ## StalkShape 2.6858568 StalkShape ## StalkColorBelowRing 2.5570551 StalkColorBelowRing ## RingNumber 2.0463027 RingNumber ## StalkColorAboveRing 1.9823127 StalkColorAboveRing ## CapSurface 1.0200298 CapSurface ## CapShape 0,5779989 CapShape ## VeilColor 0,1522645 VeilColor ## GillAttachment 0,0275000 GillAttachment ## VeilType 0,0000000 VeilType907Я решил использовать модель, чтобы попытаться предсказать, является ли гриб съедобным или ядовитым, на основе набора обучающих данных. Он идеально предсказал переменную ответа - без ложных срабатываний или ложных срабатываний.
# Predicting response variabledata.dev $ predicted.response = pred (rf, data.dev) # Create Confusion Matrixprint (confusionMatrix (data = data.dev $ predicted.response, reference = data.dev $ Edible, positive = ') Съедобный ')) ## Матрица неточностей и статистика #### Ссылка ## Прогноз Съедобный Ядовитый ## Съедобный 200 0 ## Ядовитый 0 203 #### Точность: 1 ## 95% ДИ: (0,9909, 1) ## Нет информации Скорость: 0,5037 ## Значение P [Acc> NIR]: <2.2e-16 #### Каппа: 1 ## P-значение теста Макнемара: NA #### Чувствительность: 1.0000 ## Специфичность: 1.0000 ## Pos Pred Value: 1.0000 ## Neg Pred Value: 1.0000 ## Распространенность: 0,4963 ## Скорость обнаружения: 0,4963 ## Распространенность обнаружения: 0,4963 ## Сбалансированная точность: 1,0000 #### 'Положительный' Класс: СъедобныйТеперь пришло время посмотреть, как модель справится с данными, которых она раньше не видела, - сделать прогнозы на основе тестовых данных.Он проделал достойную работу. Он имел точность 99% с очень узким доверительным интервалом. У него действительно было 48 ложных отрицательных результатов и 8 ложных срабатываний (что могло быть смертельно опасным, если бы вы действительно решили есть грибы на основе этой модели).
# Прогнозируемая переменная ответа data.val $ predicted.response <- pred (rf, data.val) # Создать матрицу путаницы 'Съедобный')) ## Матрица неточностей и статистика #### Ссылка ## Прогноз Съедобный Ядовитый ## Съедобный 3960 8 ## Ядовитый 48 3705 #### Точность: 0.9927 ## 95% ДИ: (0,9906, 0,9945) ## Нет информации Скорость: 0,5191 ## Значение P [Acc> NIR]: <2,2e-16 #### Каппа: 0,9855 ## Значение P теста Макнемара: 1.872e-07 #### Чувствительность: 0,9880 ## Специфичность: 0,9978 ## Pos Pred Value: 0,9980 ## Neg Pred Value: 0,9872 ## Распространенность: 0,5191 ## Скорость обнаружения: 0,5129 ## Распространенность обнаружения: 0,5139 ## Сбалансированная Точность: 0,9929 #### 'Положительный' Класс: СъедобныйК сожалению, я понятия не имею, насколько надежны эти данные и как они были получены.Вероятно, есть некоторая справочная информация, и я бы никогда не выбрал, есть ли неизвестный гриб на основе этой модели (и вы тоже не должны). Код, используемый в этом посте, находится на моем GitHub
Классификация качества грибов с машинным обучением
Основные особенности
- •
Глубокая нейронная сеть может эффективно классифицировать икру вешенки.
- •
Трехмерная цветовая гистограмма - полезная функция для обнаружения заражения, которая может появиться в любом месте и любой ориентации.
- •
Использование методов предварительной обработки, PCA и масштабирования может сократить время обработки и повысить точность.
- •
Этот подход может быть применен к другим типам грибов с другими наборами данных.
Реферат
Во время инкубации нереста при выращивании грибов нерест может быть заражен различными вредителями и патогенными плесневыми грибами, которые вызывают опасные повреждения урожая. Зараженные нерестилища необходимо классифицировать и выбросить, прежде чем они попадут на стадию плодоношения.На большинстве грибных хозяйств люди визуально классифицируют нерест, что является трудоемким процессом и подвержено человеческим ошибкам. Чтобы решить эту проблему, мы разработали алгоритм машинного обучения для классификации нереста вешенки ( Pleurotus ostreatus ). Образцы икры были собраны на ферме в Таиланде. Образцы представляющих интерес областей нерестилищ в полипропиленовых полипропиленовых мешках были извлечены и отфильтрованы для уменьшения шума. Трехмерные гистограммы этих регионов использовались в качестве признака. Мы проанализировали влияние двух методов, включая масштабирование функций и сжатие функций, с помощью анализа основных компонентов (PCA) на этапе предварительной обработки.Мы измерили производительность пяти классификаторов машинного обучения: опорных векторных машин (SVM), классификатора ближайшего центроида (NCC), k-ближайшего соседа (KNN), глубокой нейронной сети (DNN) и деревьев решений. Были оптимизированы параметры методов и сравнены общие характеристики. Хотя количество полученных выборок было ограниченным и несбалансированным, 4-кратная перекрестная проверка показала, что классификатор DNN имел наивысшую точность 98,8% при остаточной дисперсии 2,5%. Таким образом, наш алгоритм может быть эффективно использован для создания модели для дальнейшего применения во встроенной системе классификации грибов.
Ключевые слова
Вешенка
Культивирование в мешках
Классификация порождений
Машинное обучение
Автоматизация сельского хозяйства
Рекомендуемые статьиЦитирующие статьи (0)
Полный текст© 2020 Elsevier B.V. Все права защищены.