Обучение древней науке Спас в городе Москва. 2020-09-04
В г. Москве занятия проводятся регулярно.
Для записи в ближайшую группу заполните заявку.
Спас — древняя наука об энергетической подготовке человека к задачам жизни мирной и экстремальной. Благодаря А.М. Скульскому (родовому хранителю знаний) она дошла до наших дней.
Наука эта применялась не только для выживания на поле битвы, но и в повседневной жизни. Она направлена на решение задач связанных со здоровьем, накоплением энергетической силы, предвидением ситуаций и влиянием на жизненные события.
По сему Спас отлично подходит и для нужд современного человека. Как людям обычным, так и тем, чьи профессии связаны с риском для жизни или здоровья. Всем для кого важны: скорость реакции, умение различить воздействия, психическая выносливость, эзотерическая защита. Всё это даёт освоение трёх ступеней Спаса.
Обучает: Эрик Волк (Спасом занимается с 1999 г., преподаванием с 2015 г.)
Обучение конечно и не длится годами. Перерыв между ступенями рекомендуется не менее 1,5 месяца. Прошедшие все три ступени далее в опёке не нуждаются. Все необходимые преобразования по Спасу будут завершены.
Передача идёт полностью, каждый возьмёт сколько сможет. И сможет пустить далее по своему роду.
_____________________________________________
Программа обучения:
www.spasist.ru/obuchenie-spasu
_____________________________________________
Правила обучения:
www.spasist.ru/nashi-pravila
Не принимаются на обучение:
— беременные на любом сроке беременности;
— люди с психическими заболеваниями или неустойчивой психикой;
— при возрасте моложе 27 лет необходимо дополнительное согласование.
Мы оставляем за собой право отказывать в обучении любому без объяснения причин на любом этапе обучения.
______________________________________________Обучение Спасу даёт определённую личностную трансформацию. Если у вас есть семья, то обучаться лучше вдвоём. Поэтому для семейных пар скидка 10%.
Длительность обучения в г. Москва:
1 ступень — 3 дня (5 занятий)
2 ступень — 2 или 4 дня (4 занятия)
3 ступень — 2 дня (корректируется индивидуально)
Записаться можно, заполнив форму
Пожалуйста, не забывайте указывать в анкете город проживания Москва
Расписание ближайших занятий
1 ступень
- 04.09.2020, с 19:00 до 21:00
- 05.09.2020, с 11:00 до 18:00
- 06.09.2020, с 11:00 до 18:00
Адрес проведения: Центр «Шамбала», ул. Марксистская, д. 9. (м.Пролетарская/м.Крестьянская застава)
2 ступень
- 07.09.2020, с 19:00 до 21:00
- 08.09.2020, с 19:00 до 21:00
- 09.09.2020, с 18:00 до 22:00
- 10.09.2020, с 18:00 до 22:00
Адрес проведения: Центр «Шамбала», ул. Марксистская, д. 9. (м.Пролетарская/м.Крестьянская застава)
3 ступень
- 07.09.2020, с 11:00 до 17:00
- 08.09.2020, с 11:00 до 17:00
- 09.09.2020, с 11:00 до 17:00
Адрес проведения: Центр «Шамбала», ул. Марксистская, д. 9. (м.Пролетарская/м.Крестьянская застава).
Наши правила
Друзья, обучая Спасу, мы были в разных городах России и встречали много красивых душой и поведением людей. И для них, то что сейчас нам предстоит озвучить, понятно и без пояснений. Но не все люди одинаковы и правила, по которым вы должны обучаться, мы оглашаем открыто.
Пояснения идут перед обучением, могут быть уточнены и в ходе обучения, но если нами принимается решение об отчислении, то объяснений не будет. Потому что если не наступило понимание до, то не наступит оно и после.
1. Приходя на обучение обучайтесь.
Не нужно преследовать какие-либо другие цели. Ваша задача — максимаьлно включиться в процесс обучения.
2. Запрет на рекламу своих услуг.
Не следует заманивать людей к себе попытками “обнаружить” на них “порчу”, “сглаз” и тому подобное, предлагая почистить или вылечить их. Мы наблюдаем, и если видим, что поведение не меняется, то человек не получает приглашение на прохождение следующей ступени.
— 2. 1. То же правило действует и на все виды других услуг.
— 2. 2. Этот же запрет действует и в чатах обсуждений по Спасу.
3. Субординация.
Во время обучения мы, с согласия всех, придерживаемся общения на “ты”. Ошибочно будет принимать это как приглашение к фамильярности. Между преподавателем и обучающимися должна сохраняться принятая дистанция.
4. Соревновательность.
Мы не “меряемся” энергетической силой и не советуем никому этого делать. Процесс обучения это особый процесс и в нём существуют свои состояния. На обучении, энергетически, мы открыты и доброжелательны. Но неуважительное отношение к происходящему и к нам, может закончиться плачевно.
5. Переход на следующую ступень по согласованию.
Для того чтобы прийти на следующую ступень нужно получить приглашение. Приходить без приглашения не нужно. Мы рассылаем письма уведомления с адреса [email protected], добавьте его в белый список или в адресную книгу. Если мы не получили ответ на почту, то звоним по телефону, чтобы пригласить на следующую ступень.
6. Гаджеты.
Запрещено использовать мобильные гаджеты. Все телефоны необходимо перевести в беззвучный режим. В исключительных случая разрешено использовать вибро-режим.
7. Тактичность.
Если у вас возник вопрос дослушайте мысль преподавателя, возможно ответ на него прозвучит. Если вопрос всё-таки остался, то поднимите руку и дождитесь, когда вам дадут слово. Не говорите одновременно с другим человеком, тем более с преподавателем. Мы всячески приветствуем вопросы на обучении. И при соблюдении порядка в группе сможем ответить на гораздо большее их число.
8. Ясность понимания и духовные ценности.
На обучение приходят люди с разным мировоззрением и ценностями. Спас вне религий. Спас — это древнее дорелигиозное точное знание об энергетическом устройстве человека и его возможностях. При обучении неизбежны пересмотры устоявшихся представлений. Иногда это бывает эмоционально сложно, срабатывают защиты и обучающиеся делают неверные умозаключения. Большая просьба, при недопонимании обязательно оглашайте его. Не отмалчивайтесь. Если вы почувствовали что вас что-то эмоционально задевает, что идёт волна внутреннего несогласия, то ваша ответственность в том, чтобы сказать об этом. Мы сможем подобрать другие слова для объяснения сути явления, если будем знать что с вами происходит. Мы не раз видели, как при уточнённом пояснении наступает ясность понимания и уходит напряжение. Но также выяснялось, что не все решаются говорить в группе открыто и мучаются от домыслов. Поэтому это ваша ответственность задать нужный вопрос. Мы отвечаем за то что говорим, но за то как вы это поняли отвечаете вы. ⚡
9. Целостность трёх ступеней.
Этот пункт носит рекомендательный характер. Сборка по Спасу — это неразрывный процесс. Для более экологичной и плавной передачи он не делается разом. С такой нагрузкой психика современного человека не справляется. Поэтому сборка идёт в три ступени, все они необходимые этапы единого процесса. Весьма рекомендуем проходить обучение по Спасу цельно. Не начинать других обучений. За полгода вы вряд ли что-то пропустите. Вы вполне можете продолжать те практики, которые вами уже освоены. Речь идёт именно о новых обучениях.
10. Психоактивные вещества.
Если вы ещё не определили для себя употребление наркотиков как неприемлемое, то просим на время обучения не принимать алкоголь. Про другие виды даже и говорить не приходится. По никотину данное правило носит рекомендательных характер. Однако замечено, что если воздержаться от него на три дня обучения, то желание закурить может и не вернуться. Самое правильное на наш взгляд, отнестись к этому как к шансу. Воздержитесь от приёма обезболивающих.
Отдельно хочется остановиться на опозданиях. Опоздавшие более чем на 10 минут на первое занятие первой ступени на обучение не принимаются; для записи в следующую группу проходят повторное согласование.
Обучение древней науке Спас в городе Санкт-Петербург. 2020-09-11
В г. Санкт-Петербурге занятия проводятся регулярно.
Для записи в ближайшую группу заполните заявку.
Спас — древняя наука об энергетической подготовке человека к задачам жизни мирной и экстремальной. Благодаря А.М. Скульскому (родовому хранителю знаний) она дошла до наших дней.
Наука эта применялась не только для выживания на поле битвы, но и в повседневной жизни. Она направлена на решение задач связанных со здоровьем, накоплением энергетической силы, предвидением ситуаций и влиянием на жизненные события.
По сему Спас отлично подходит и для нужд современного человека. Как людям обычным, так и тем, чьи профессии связаны с риском для жизни или здоровья. Всем для кого важны: скорость реакции, умение различить воздействия, психическая выносливость, эзотерическая защита. Всё это даёт освоение трёх ступеней Спаса.
Обучает: Эрик Волк (Спасом занимается с 1999 г., преподаванием с 2015 г.)
Обучение конечно и не длится годами. Перерыв между ступенями рекомендуется не менее 1,5 месяца. Прошедшие все три ступени далее в опёке не нуждаются. Все необходимые преобразования по Спасу будут завершены.
Передача идёт полностью, каждый возьмёт сколько сможет. И сможет пустить далее по своему роду.
_____________________________________________
Программа обучения:
www.spasist.ru/obuchenie-spasu
_____________________________________________
Правила обучения:
www.spasist.ru/nashi-pravila
Не принимаются на обучение:
— беременные на любом сроке беременности;
— люди с психическими заболеваниями или неустойчивой психикой;
— при возрасте моложе 27 лет необходимо дополнительное согласование.
Мы оставляем за собой право отказывать в обучении любому без объяснения причин на любом этапе обучения.
______________________________________________
Обучение Спасу даёт определённую личностную трансформацию. Если у вас есть семья, то обучаться лучше вдвоём. Поэтому для семейных пар скидка 10%.
Длительность обучения в г. Санкт-Петербург:
1 ступень — 3 дня (5 занятий)
2 ступень — 2 или 4 дня (4 занятия)
3 ступень — 2 дня (корректируется индивидуально)
Записаться можно, заполнив форму
Пожалуйста, не забывайте указывать в анкете город проживания Санкт-Петербург
Расписание ближайших занятий
1 ступень
- 11.09.2020, с 19:00 до 21:00
- 12.09.2020, с 11:00 до 18:00
- 13.09.2020, с 11:00 до 18:00
Адрес проведения: В.О. ул Железноводская дом 17/5. Пожалуйста, возьмите с собой сменную обувь.
2 ступень
- 14.09.2020, с 19:00 до 21:00
- 15.09.2020, с 19:00 до 21:00
- 16.09.2020, с 18:00 до 22:00
- 17.09.2020, с 18:00 до 22:00
Адрес проведения: В.О. ул Железноводская дом 17/5. Пожалуйста, возьмите с собой сменную обувь.
3 ступень
- 14.09.2020, с 11:00 до 17:00
- 15.09.2020, с 11:00 до 17:00
- 16.09.2020, с 11:00 до 17:00
Родовая легенда. С чего начинается обучение спасу? — Круг «Сколот»
С этих слов ранее начиналось обучение Спасу, с этих слов обучение начинается и теперь.
«Человек – это Божественное растение. На этом растении растут и созревают девять Божественных зерен. Первого зовут Серебряный человек, второго – Даж, третью – Малка, Сак– четвертого, Вол – пятого, Кален – шестого, Хор – седьмого, Тар – восьмого, Швак – девятого. Есть еще два лунных Смарг (Троян) и Маара.
Над всеми стоит Родовой ангел.»
 С чего начинается обучение Спасу?
С чего начинается обучение Спасу?В теле человека живут «Железный человек» и «Серебряный человек», который выходит из тела прозрачной серебристой полосой.
«Серебряный человек» носит тоже имя что и человеку при рождении дали. Чтобы не путать «Серебряного человека» с телом мы зовем его просто «Сяйво».
Физическое тело называется Глина – это Божественный стебель. Стебель окружают три слоя коры, прозрачных, как испарение над землей при пахоте или как утренний туман над рекой. Как неуловимая дымка, но если тебе покажут где она, то ты сможешь её увидеть.
Первый слой на расстоянии одного-двух пальцев от физического тела, зовут его «Сяйво». Сяйво- энергетический слой, который является для физического тела и человека своего рода переводчиком в подаче и приёме информации между ним и остальными энергетическими полями. Является основой для формирования энергетической системы после перехода физического тела из этой жизни.
Второй слой коры на расстоянии ладони, его зовут «Даж». Даж — питает и связывает все органы физического тела в единую систему.
Третьй слой – на расстоянии локтя – «Малка» (Малка – женского рода – Берегиня). Малка – внешняя оболочка базовой системы человека, защищающая его от проникновения извне энергетических нападений (сглаз, порча), паразитов (лярвы, подселения).
С этим рождается ребенок. С этим он живет до двенадцати – пятнадцати лет. С двенадцати – пятнадцати лет божий стебель выпускает из себя ветви, на которые садятся божьи птицы (Спутники).
Откуда они приходят, никто не знает. Возможно, Бог дает, а может, с умирающих родственников перелетают. Возможно, так же покидают глупых людей.
Сак – энергетическое тело – находится слева у тазобедренного сустава, самостоятельно может передвигаться от 1,5 до 30 метров. Защищает и управляет органами малого таза, после смерти физического тела становится тем, что мы называем «Божьим стеблом». Хранит информацию о физических навыках: ходить, дышать и т. п.
Вол — находится с правой стороны от физического тела. Имеет непосредственную связь с печенью и выполняет функции силовой системы эфирного организма, является своеобразными «мышцами» Сака, усиливает его движения, а также снабжает тонкой энергией физическое Тело, Сяйво, Дажа и Малку. Вол считывает сигналы Ума человека и при отсутствии отменяющего сигнала «Серебряного человека» через Даж, Малку, Сака выполняет полученные от Ума указания. Вол, может получать сигналы напрямую от сердца человека. В случае праведного гнева, может превращаться отдельную энергоструктуру. В таком случае удар праведного гнева неотразим.
Кален – Великий полоз – в родовых легендах представлен как дух Земли. Воплощает собой вечный круговорот рождения и смерти. В западной эзотерической традиции изображается как Ураборос (змея кусающая себя за хвост). Живет вне пространства и времени. Способен получать и передавать информацию на прямую человеку.
Хор – Сокол – Находится с правой стороны от физического тела. Связан с мозжечком и лобными долями головного мозга. Проявляется в виде фантома «эфирного двойника». Способен осуществлять самостоятельные действия как на эфирном, так и на физических уровнях восприятия человеческого разума. Используется для дальновидения. С помощью Хора можно устанавливать телепатическую связь с животными.
Тар – Волк – символизирует генную память. Находится с левой стороны от физического тела, полностью автономен. С ним человек может только советоваться. Серый волк из народных сказок. Подключение Тара воспринимается человеческим сознанием и описывается как снисхождение «Святого Духа».
Швак – Медведь – ассоциируется с древней мудростью народа и его духовными ценностями. Выбирает носителя самостоятельно. Активируется самостоятельно если выживанию человека грозит смертельная опасность.Полное включение Швака может восприниматься как просветление.
Два лунных спутника Смаргл и Маара.
Ассоциируются с растущей и убывающей луной.
Над всем энергокомплеском человека стоит Родовой ангел.
Индивидуальное обучение Спасу
Это эксклюзивный вариант обучения.
Он рассчитан на людей, которые по тем или иным причинам не могут (не хотят) заниматься вместе с посторонними людьми. Кто-то не хочет «светиться», другому по должности «не положено», а кому-то требуется максимально индивидуальный подход.
Программа ориентирована на запросы бизнесменов, политиков, общественных деятелей. Основной упор делается на следующие направления: взаимодействие с людьми; корректировка собственной энергетики; надежная энергетическая защита и энергетическое воздействие; другие интересные темы.
Так как подобные запросы не редкость, мы предлагаем вариант эксклюзивного обучения.
Желающий обучаться индивидуально, подбирает себе 2-3 человека из родственников, друзей, партнеров по бизнесу, однополчан и т.д., желающих пройти вместе с ним обучение.
Для занятий вам нужно выбрать любое удобное место в любом городе.
Каждый потенциальный участник заполняет анкету для согласования, а в случае необходимости проходит и дополнительное собеседование (онлайн, через интернет). Обращаем ваше внимание, что анкета высылается после заполнения запроса и она отличается от стандартного варианта.
Со своей стороны мы готовим для вас индивидуальную программу. Вместе согласовываем длительность обучения, график и список наиболее интересующих направлений. В программу кроме методик системы Спас дополнительно включены иные способы и техники воздействия.
Индивидуальные занятия с одним человеком не рекомендуем ввиду их сниженной эффективности. В случае крайней необходимости — совместно с вами найдем решение.
Детальные условия проведения подобных семинаров согласовываются в голосовом режиме (skype, viber, телефон) после заполнения запроса.
Возможен вариант подготовки подчиненных для более эффективной работы. Программа для них более простая. Обучение подчиненных проводится только после полного обучения руководителя и определенного перерыва.
Заполнить запрос на эксклюзивное обучение.
Спас — древняя наука об энергетике человека
За последние несколько десятилетий Спас получил широкое распространение.
Что же это за наука такая?
Пожалуй самое точное определение в своей книге дает А.М. Скульский — современный разработчик этой системы. Он пишет: «Спас – особое состояние психики, в которое сознательно входит человек для раскрытия своих сверхъестественных сенситивных способностей с целью решения неординарных задач, которые обычными методами не имеют решения».
По нашему мнению Спас позволяет человеку находиться в гармонии с собой и со всем окружающим миром. Управлять собой в стрессовых состояниях, а также осознанно входить и выходить из них. Дает психологическую независимость, освобождая ваш мозг от предрассудков, суеверий и других бесконечных дестабилизирующих факторов, которыми наполнен современный мир и влиянию которых подвержен современный человек.
Даже больше. Спас — это состояние в котором живет человек, а вот глубина этого состояния регулируется, в зависимости от жизненной необходимости.
При полном раскрытии потенциала по Спасу человек получает многие возможности в энергетическом, психо-эмоциональном и ментальном уровнях. Он полностью опирается на себя, отдавая полный отчет всем своим действиям и последствиям. Может не зависеть от эгрегоров, ни от религиозных, ни от каких-либо других.
Познав Спас, человек познает устройство своего энергетического организма, научается им управлять и действует с его помощью в обыденной жизни, наряду с привычным физическим телом.
С биоэнергетической точки зрения настоящий Спас — это ключ. Возможность использовать любые системы знаний и технологии воздействия, подстраивать их под себя, не впадая в зависимость от них. Это ключ к свободе восприятия без использования субъективных понятий, навязанных нам в результате жизни в социуме.
Доподлинно сказать когда, из какого источника вышел и дошел до наших дней Спас мы не можем. Как складывалось его течение во времени и пространстве, по каким оно шло территориям и народам и скрыто течёт и сейчас — на все эти вопросы могут быть лишь версии. Подлинной, достоверной историей, той науки, которая сегодня называется Спас, мы не располагаем. У нас, как исследователей, есть много вопросов. На каком этапе это знание получило сегодняшнее название? Под какими другими именами оно раньше проявлялось в миру? Только в наши дни его называют: “Спас Великий”, “Спас Причерноморья”, “Спас”, “Спас казачий”. Разные названия одной системы практических знаний.
Одним своим руслом оно пришло к казакам и наиболее ярко было проявлено характерниками и сечевиками. Это, пожалуй, самое близкое к нашим дням историческое его проявление. Однако, Спас жив и сегодня.
В основе нашего курса лежит Спас, восстановленный из глубины веков и разработанный А.М. Скульским, доработанный и адаптированный нами для людей с развитым мышлением, широкими знаниями и устойчивой психикой.
Энергетика, собранная по Спасу — это совершенно не конец развития, это базовый необходимый этап для дальнейшего роста.
С 2015 года наша команда ведет постоянную разработку и исследования на базе данной системы. По мере систематизации полученных и проверенных данных мы добавляем их в программу обучения.
Занятия проводятся на территории России (другие регионы согласовываются отдельно).
Предлагаем ознакомиться с программой обучения и краткой историей развития современной системы Спас.
С октября 2019 года мы начали подготовку преподавателей Спаса.
Мы по-прежнему (с 1999 года) ищем людей, владеющих родовыми знаниями, для обмена опытом.
Расписание семинаров в городах
г. Барнаул
Первая ступень
11 декабря 2020 19:00 — 21:00
12 декабря 2020 11:00 — 18:00
13 декабря 2020 11:00 — 18:00
Вторая ступень
Третья ступень
scikit-learn: Сохранение и восстановление моделей
Во многих случаях при работе с библиотекой scikit-learn вам необходимо сохранить свои модели прогнозов в файл, а затем восстановить их, чтобы повторно использовать вашу предыдущую работу для: тестирования модели на новых данных, сравнения нескольких моделей, или что-нибудь еще. Эта процедура сохранения также известна как сериализация объекта — представляет собой объект с потоком байтов, чтобы сохранить его на диске, отправить по сети или сохранить в базе данных, в то время как процедура восстановления известна как десериализация.В этой статье мы рассмотрим три возможных способа сделать это в Python и scikit-learn, каждый из которых имеет свои плюсы и минусы.
Инструменты для сохранения и восстановления моделей
Первый инструмент, который мы описываем, — это Pickle, стандартный инструмент Python для (де) сериализации объектов. После этого мы рассмотрим библиотеку Joblib, которая предлагает простую (де) сериализацию объектов, содержащих большие массивы данных, и, наконец, мы представляем ручной подход для сохранения и восстановления объектов в / из JSON (нотация объектов JavaScript).Ни один из этих подходов не представляет собой оптимального решения, но правильный выбор следует выбирать в соответствии с потребностями вашего проекта.
Инициализация модели
Для начала создадим одну scikit-learn модель. В нашем примере мы будем использовать модель логистической регрессии и набор данных Iris. Импортируем необходимые библиотеки, загрузим данные и разделим их на обучающий и тестовый наборы.
из sklearn.linear_model import LogisticRegression
из sklearn.datasets импортировать load_iris
из склеарна.model_selection импорт train_test_split
# Загрузить и разделить данные
данные = load_iris ()
Xtrain, Xtest, Ytrain, Ytest = train_test_split (data.data, data.target, test_size = 0.3, random_state = 4)
Теперь давайте создадим модель с некоторыми параметрами, отличными от параметров по умолчанию, и подгоним ее под данные обучения. Мы предполагаем, что вы ранее нашли оптимальные параметры модели, то есть те, которые обеспечивают наивысшую расчетную точность.
# Создать модель
model = LogisticRegression (C = 0.1,
max_iter = 20,
fit_intercept = Верно,
n_jobs = 3,
solver = 'liblinear')
model.fit (Xtrain, Ytrain)
И наша получившаяся модель:
Логистическая регрессия (C = 0,1, class_weight = None, dual = False, fit_intercept = True,
intercept_scaling = 1, max_iter = 20, multi_class = 'ovr', n_jobs = 3,
штраф = 'l2', random_state = None, solver = 'liblinear', tol = 0,0001,
verbose = 0, warm_start = False)
Используя метод подгонки , модель узнала свои коэффициенты, которые хранятся в модели .coef_ . Цель состоит в том, чтобы сохранить параметры и коэффициенты модели в файл, чтобы вам не нужно было снова повторять шаги обучения модели и оптимизации параметров для новых данных.
Модуль рассола
В следующих нескольких строках кода модель, которую мы создали на предыдущем шаге, сохраняется в файл, а затем загружается как новый объект с именем pickled_model . Затем загруженная модель используется для расчета показателя точности и прогнозирования результатов на новых невидимых (тестовых) данных.
маринад импортный
#
# Создайте свою модель здесь (как указано выше)
#
# Сохранить в файл в текущем рабочем каталоге
pkl_filename = "pickle_model.pkl"
с открытым (pkl_filename, 'wb') как файл:
pickle.dump (модель, файл)
# Загрузить из файла
с открытым (pkl_filename, 'rb') как файл:
pickle_model = pickle.load (файл)
# Рассчитать показатель точности и предсказать целевые значения
оценка = pickle_model.score (Xtest, Ytest)
print ("Результат теста: {0: .2f}%". format (100 * оценка))
Ypredict = pickle_model.предсказать (Xtest)
Запуск этого кода должен дать ваш результат и сохранить модель через Pickle:
$ python save_model_pickle.py
Результат теста: 91,11%
Самое замечательное в использовании Pickle для сохранения и восстановления наших моделей обучения заключается в том, что это быстро — вы можете сделать это в двух строках кода. Это полезно, если вы оптимизировали параметры модели на обучающих данных, поэтому вам не нужно повторять этот шаг снова. В любом случае, он не сохраняет результаты тестов или какие-либо данные.Тем не менее, вы можете сделать это, сохранив кортеж или список из нескольких объектов (и запомните, какой объект куда идет) следующим образом:
tuple_objects = (модель, Xtrain, Ytrain, оценка)
# Сохранить кортеж
pickle.dump (tuple_objects, open ("tuple_model.pkl", 'wb'))
# Восстановить кортеж
pickled_model, pickled_Xtrain, pickled_Ytrain, pickled_score = pickle.load (open ("tuple_model.pkl", 'rb'))
Модуль Joblib
Библиотека Joblib предназначена для замены Pickle для объектов, содержащих большие данные.Повторим процедуру сохранения и восстановления, как и в случае с Pickle.
из sklearn.externals import joblib
# Сохранить в файл в текущем рабочем каталоге
joblib_file = "joblib_model.pkl"
joblib.dump (модель, joblib_file)
# Загрузить из файла
joblib_model = joblib.load (joblib_file)
# Рассчитываем точность и прогнозы
score = joblib_model.score (Xtest, Ytest)
print ("Результат теста: {0: .2f}%". format (100 * оценка))
Ypredict = pickle_model.predict (Xtest)
$ python save_model_joblib.ру
Результат теста: 91,11%
Как видно из примера, библиотека Joblib предлагает немного более простой рабочий процесс по сравнению с Pickle. В то время как Pickle требует передачи файлового объекта в качестве аргумента, Joblib работает как с файловыми объектами, так и с строковыми именами файлов. Если ваша модель содержит большие массивы данных, каждый массив будет храниться в отдельном файле, но процедура сохранения и восстановления будет
.3,4. Сохраняемость модели — документация scikit-learn 0.23.2
После обучения модели scikit-learn желательно иметь способ сохранения модель для будущего использования без переобучения. В следующем разделе дается вы пример того, как сохранить модель с рассолом. Мы также рассмотрим несколько проблемы безопасности и ремонтопригодности при работе с сериализацией pickle.
Альтернативой травлению является экспорт модели в другой формат с использованием одного инструментов экспорта модели, перечисленных в разделе «Связанные проекты».в отличие травление, после экспорта вы не сможете восстановить полную оценку Scikit-learn объект, но вы можете развернуть модель для прогнозирования, обычно с помощью инструментов поддержка открытых форматов обмена моделями, таких как ONNX или PMML.
3.4.1. Пример стойкости
Можно сохранить модель в scikit-learn с помощью встроенного в Python модель настойчивости, а именно рассол:
>>> из sklearn import svm >>> из наборов данных импорта sklearn >>> clf = svm.SVC () >>> X, y = datasets.load_iris (return_X_y = True) >>> clf.fit (X, y) SVC () >>> импортный рассол >>> s = pickle.dumps (clf) >>> clf2 = pickle.loads >>> clf2.predict (X [0: 1]) массив ([0]) >>> y [0] 0
В конкретном случае scikit-learn может быть лучше использовать joblib’s
замена рассола ( отвал и загрузка ), что более эффективно на
объекты, которые несут внутри большие массивы numpy, как это часто бывает для
приспособлены оценки scikit-learn, но могут копировать только на диск, а не на
строка:
>>> из дампа импорта joblib, загрузить >>> dump (clf, 'имя_файла.joblib ')
Позже вы можете загрузить обратно маринованную модель (возможно, в другом процессе Python) с:
>>> clf = load ('filename.joblib')
Примечание
дамп и загрузка функций также принимают файловый объект
вместо имен файлов. Дополнительная информация о сохранении данных с помощью Joblib находится
доступна здесь.
3.4.2. Ограничения безопасности и ремонтопригодности
pickle (и с расширением joblib), имеет некоторые проблемы с ремонтопригодностью и безопасность.Из-за этого
Никогда не извлекайте ненадежные данные, так как это может привести к заражению вредоносным кодом. выполняется при загрузке.
Хотя модели, сохраненные с использованием одной версии scikit-learn, могут загружаться в в других версиях это полностью не поддерживается и не рекомендуется. Должно также следует иметь в виду, что операции, выполняемые с такими данными, могут дать разные и неожиданные результаты.
Чтобы перестроить аналогичную модель с будущими версиями scikit-learn, дополнительные метаданные должны быть сохранены вдоль маринованной модели:
Обучающие данные, e.грамм. ссылка на неизменяемый снимок
Исходный код Python, используемый для создания модели
Версии scikit-learn и его зависимости
Оценка перекрестной проверки, полученная на обучающих данных
Это должно позволить проверить, что оценка перекрестной проверки находится в тот же диапазон, что и раньше.
Поскольку внутреннее представление модели может отличаться на двух разных архитектуры, выгрузив модель на одну архитектуру и загрузив ее на другая архитектура не поддерживается.
Если вы хотите узнать больше об этих проблемах и изучить другие возможные методы сериализации, обратитесь к этому разговор Алекса Гейнора.
.Иллюстрированный BERT, ELMo и компания. (Как NLP Cracked Transfer Learning) — Джей Аламмар — Визуализация машинного обучения по одной концепции за раз.
Обсуждения:
Hacker News (98 баллов, 19 комментариев), Reddit r / MachineLearning (164 балла, 20 комментариев)
Переводы: Китайский (упрощенный), Корейский, Персидский, Русский, Японский
2018 год стал переломным для моделей машинного обучения, обрабатывающих текст (или, точнее, обработки естественного языка или NLP для краткости).Наше концептуальное понимание того, как лучше всего представлять слова и предложения таким образом, чтобы лучше всего улавливать лежащие в их основе значения и отношения, быстро развивается. Более того, сообщество НЛП выдвигает невероятно мощные компоненты, которые вы можете бесплатно загружать и использовать в своих собственных моделях и конвейерах (это называется моментом ImageNet в НЛП, ссылаясь на то, как много лет назад подобные разработки ускорили развитие машинного обучения в компьютерном зрении. задачи).
(ULM-FiT не имеет ничего общего с Cookie Monster.Но больше ни о чем думать не мог ..)
Одной из последних вех в этом развитии является выпуск BERT, событие, которое описывается как начало новой эры в НЛП. BERT — это модель, которая побила несколько рекордов того, насколько хорошо модели могут справляться с языковыми задачами. Вскоре после выпуска документа с описанием модели команда также открыла исходный код модели и сделала доступными для загрузки версии модели, которые уже были предварительно обучены на массивных наборах данных.Это важное событие, поскольку оно позволяет любому, кто создает модель машинного обучения, включающую языковую обработку, использовать эту мощную систему в качестве легкодоступного компонента, экономя время, энергию, знания и ресурсы, которые были бы потрачены на обучение модели языковой обработки с царапина.
Два этапа разработки BERT. Вы можете загрузить модель, предварительно обученную на шаге 1 (обученную на неаннотированных данных), и беспокоиться только о ее точной настройке для шага 2. [Источник для значка книги].
BERT основывается на ряде умных идей, которые в последнее время зарождаются в сообществе НЛП, включая, помимо прочего, Semi-supervised Sequence Learning (Эндрю Дай и Куок Ле), ELMo (Мэтью Петерс и исследователи из AI2). и UW CSE), ULMFiT (основателя fast.ai Джереми Ховарда и Себастьяна Рудера), преобразователя OpenAI (разработанного исследователями OpenAI Рэдфордом, Нарасимханом, Салиманом и Суцкевером) и преобразователем (Vaswani et al).
Есть ряд концепций, о которых нужно знать, чтобы правильно понять, что такое BERT.Итак, давайте начнем с рассмотрения способов использования BERT, прежде чем рассматривать концепции, включенные в саму модель.
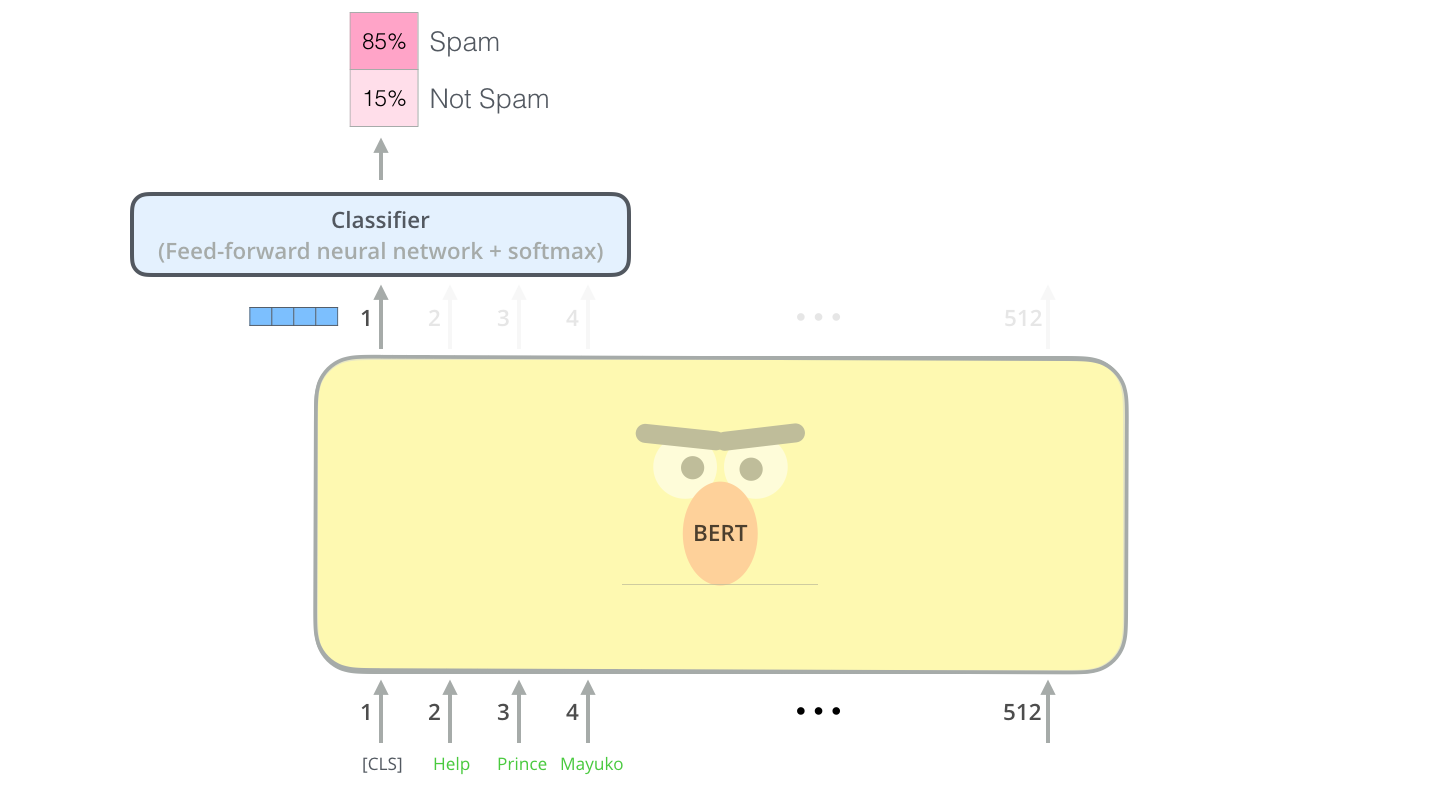
Пример: классификация предложений
Самый простой способ использовать BERT — использовать его для классификации отдельного фрагмента текста. Эта модель будет выглядеть так:
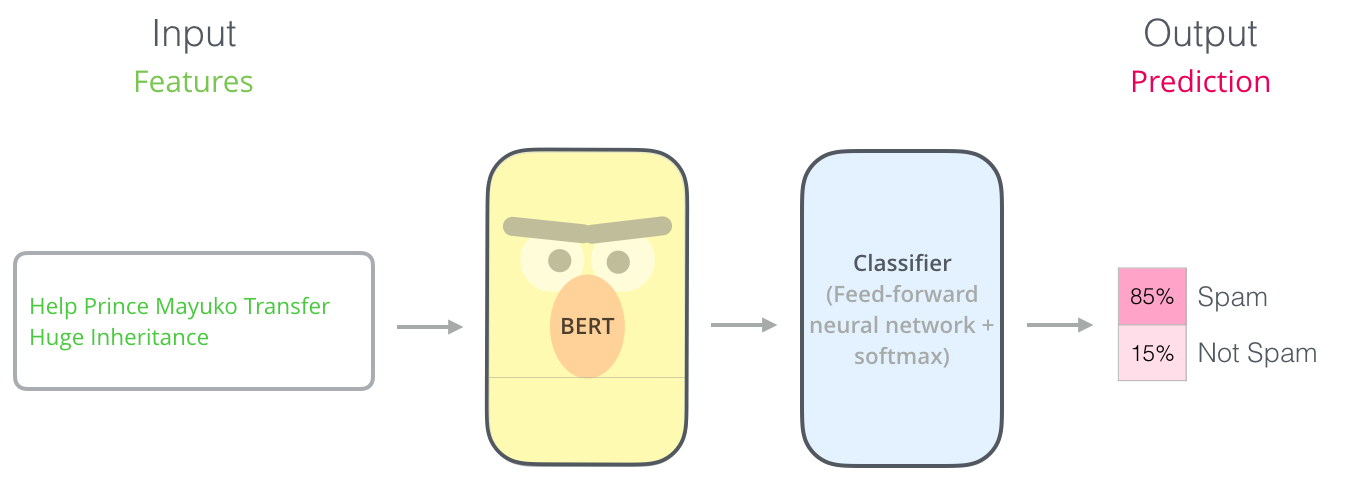
Для обучения такой модели вам в основном необходимо обучить классификатор, с минимальными изменениями, происходящими с моделью BERT на этапе обучения. Этот процесс обучения называется точной настройкой и берет свое начало в обучении с полу-контролируемой последовательностью и ULMFiT.
Для людей, не разбирающихся в теме, поскольку мы говорим о классификаторах, мы находимся в области машинного обучения с учителем. Это означало бы, что нам нужен помеченный набор данных для обучения такой модели. В этом примере классификатора спама помеченный набор данных будет списком сообщений электронной почты и меткой («спам» или «не спам» для каждого сообщения).
Другие примеры такого варианта использования включают:
- Анализ тональности
- Исходные данные: фильм / обзор продукта.Вывод: отзыв положительный или отрицательный?
- Пример набора данных: SST
- Проверка фактов
- Ввод: предложение. Вывод: «Требовать» или «Не требовать»
- Более амбициозный / футуристический пример:
- Исходные данные: Предложение о претензии. Вывод: «Верно» или «Ложь»
- Full Fact — это организация, создающая инструменты для автоматической проверки фактов на благо общества. Частью их конвейера является классификатор, который читает новостные статьи и выявляет утверждения (классифицирует текст как «утверждение» или «не утверждение»), которые впоследствии могут быть проверены фактами (теперь люди, а позже, надеюсь, ML).
- Видео: Вложения предложений для автоматизированной проверки фактов — Лев Константиновский.
Модель Архитектура
Теперь, когда у вас в голове есть пример использования BERT, давайте подробнее рассмотрим, как он работает.

В статье представлены модели BERT двух размеров:
- BERT BASE — По размеру сопоставимо с OpenAI Transformer для сравнения производительности
- BERT LARGE — смехотворно огромная модель, которая достигла самых современных результатов, описанных в документе .
BERT — это, по сути, обученный стек Transformer Encoder.Это хорошее время, чтобы посоветовать вам прочитать мой предыдущий пост The Illustrated Transformer, в котором объясняется модель Transformer — фундаментальная концепция для BERT и концепции, которые мы обсудим далее.
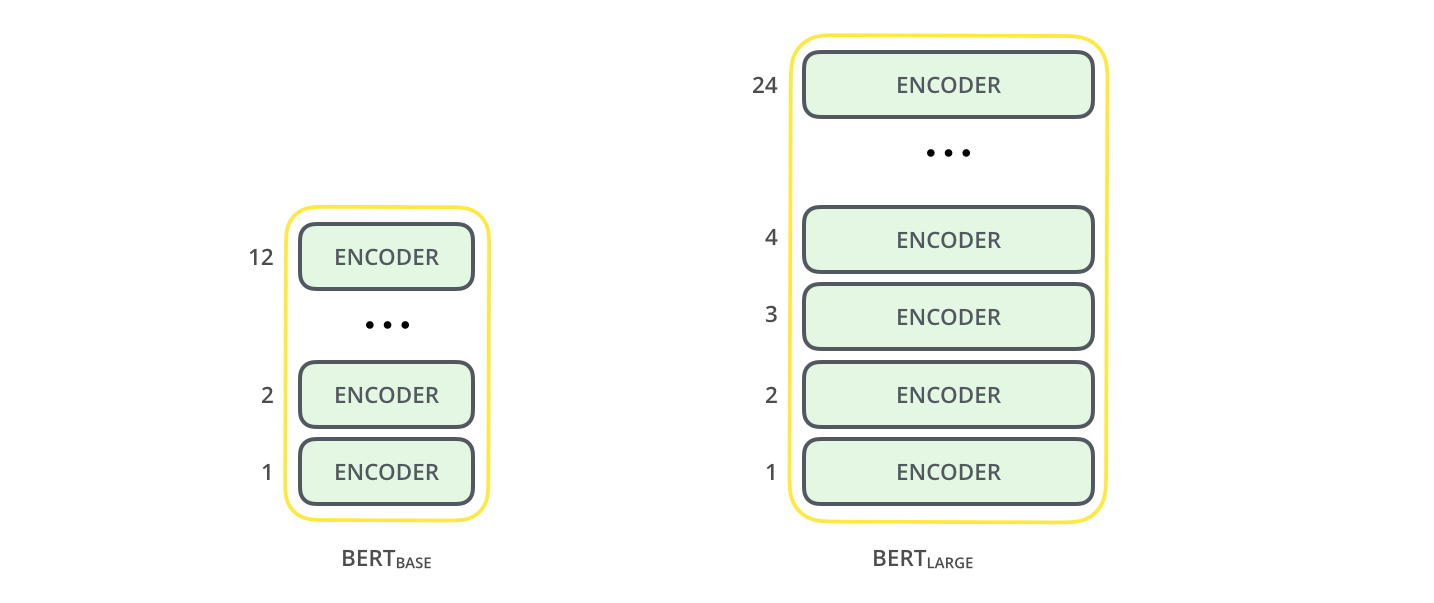
Модели BERT обоих размеров имеют большое количество слоев кодировщика (которые в статье называются блоками трансформатора) — двенадцать для базовой версии и двадцать четыре для большой версии. Они также имеют более крупные сети с прямой связью (768 и 1024 скрытых блока соответственно) и больше внимания (12 и 16 соответственно), чем конфигурация по умолчанию в эталонной реализации Transformer в исходной статье (6 уровней кодировщика, 512 скрытых блоков, и 8 глав внимания).
Входы модели
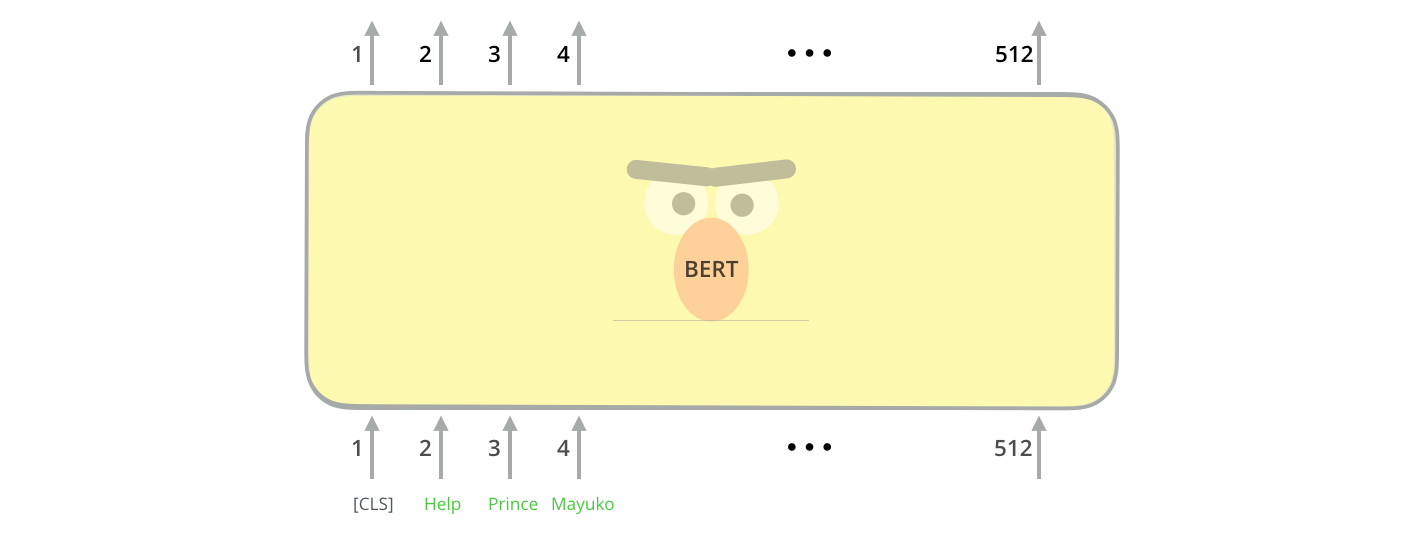
Первый входной токен снабжен специальным токеном [CLS] по причинам, которые станут очевидными позже. CLS здесь означает классификацию.
Как и обычный кодировщик преобразователя, BERT принимает в качестве входных данных последовательность слов, которые продолжают течь вверх по стеку. Каждый уровень применяет самовнимание и передает свои результаты через сеть прямого распространения, а затем передает их следующему кодировщику.

С точки зрения архитектуры, он был идентичен Transformer до этого момента (за исключением размера, который мы просто можем установить).Именно на выходе мы сначала начинаем видеть, как вещи расходятся.
МодельВыходы
Каждая позиция выводит вектор размером hidden_size (768 в BERT Base). В рассмотренном выше примере классификации предложений мы фокусируемся на выводе только первой позиции (которой мы передали специальный токен [CLS]).
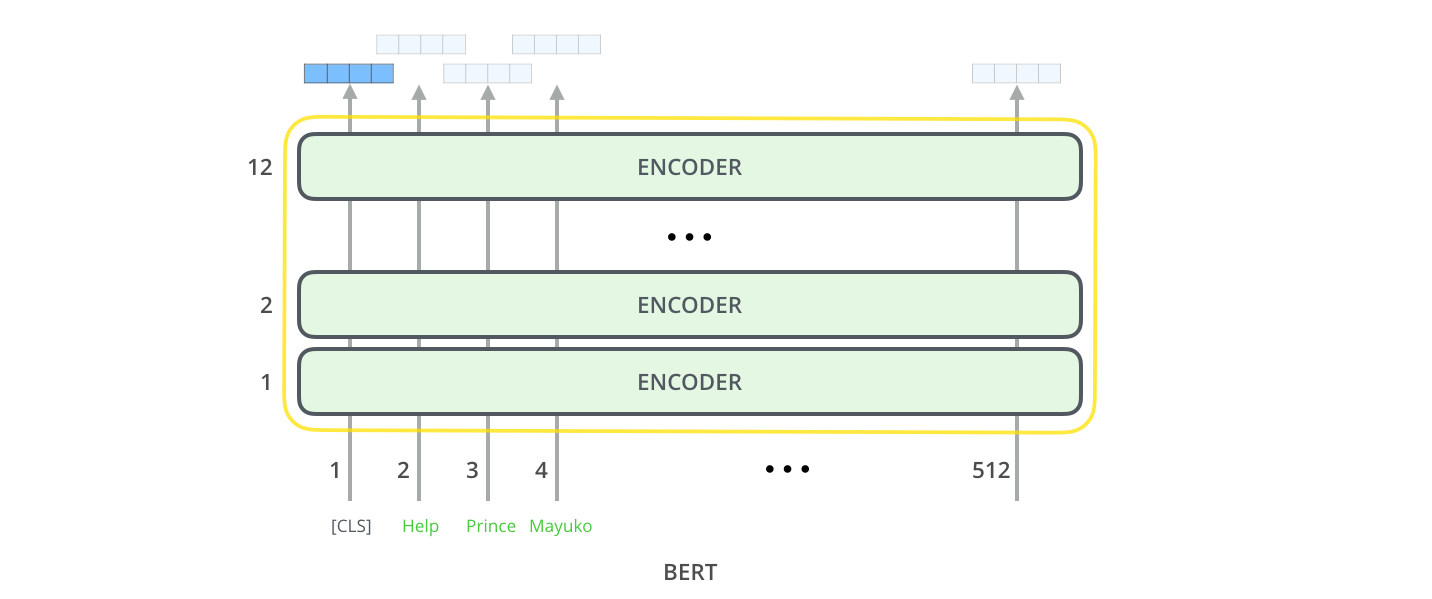
Этот вектор теперь можно использовать в качестве входных данных для выбранного нами классификатора. В статье были достигнуты отличные результаты при использовании однослойной нейронной сети в качестве классификатора.
Если у вас больше ярлыков (например, если вы являетесь почтовой службой, которая помечает электронные письма как «спам», «не спам», «социальные сети» и «продвижение»), вы просто настраиваете сеть классификаторов, чтобы иметь больше выходных нейронов которые затем проходят через softmax.
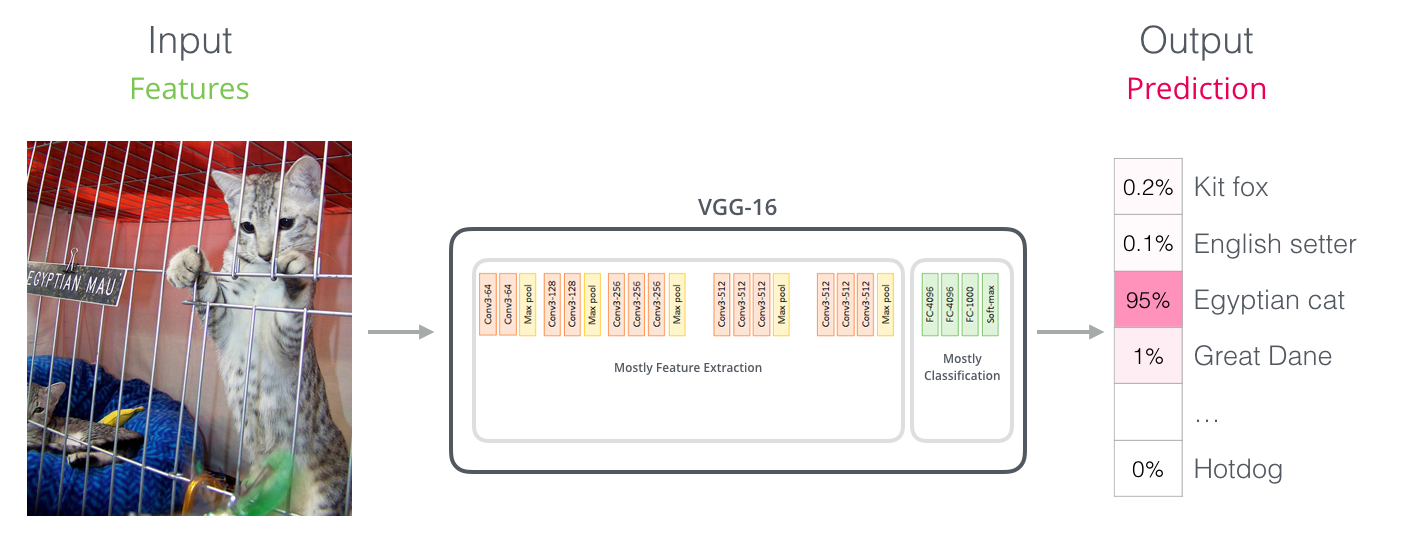
Параллели со сверточными сетями
Для тех, кто имеет опыт работы в области компьютерного зрения, эта передача вектора должна напоминать то, что происходит между сверточной частью сети, такой как VGGNet, и полностью подключенной частью классификации в конце сети.
Новая эра вложения
Эти новые разработки несут с собой новый сдвиг в способах кодирования слов. До сих пор встраивание слов было главной силой в том, как ведущие модели НЛП работают с языком. Для таких задач широко используются такие методы, как Word2Vec и Glove. Давайте вспомним, как они используются, прежде чем указывать на то, что сейчас изменилось.
Обзор встраивания слов
Для того, чтобы слова обрабатывались моделями машинного обучения, им нужна некоторая форма числового представления, которое модели могут использовать в своих вычислениях.Word2Vec показал, что мы можем использовать вектор (список чисел) для правильного представления слов таким образом, чтобы улавливать семантические или связанные со смыслом отношения (например, способность определять, похожи ли слова или противоположны, или что пара слов такие слова, как «Стокгольм» и «Швеция», имеют те же отношения между собой, что и «Каир» и «Египет» между ними), а также синтаксические или основанные на грамматике отношения (например, отношения между «имел» и «имеет» то же самое, что и между «было» и «есть»).
Специалисты быстро поняли, что это отличная идея — использовать вложения, которые были предварительно обучены на огромных объемах текстовых данных, вместо того, чтобы обучать их вместе с моделью на том, что часто было небольшим набором данных. Таким образом, стало возможным загрузить список слов и их вложений, сгенерированный путем предварительного обучения с помощью Word2Vec или GloVe. Это пример вложения слова «палка» в GloVe (с размером вектора вложения 200)
 .
.План развития веб-разработчиков на 2020 год. Научитесь быть Frontend, Backend… | Трей Хаффин
Сейчас самое лучшее время, чтобы научиться программировать или сменить профессию в разработке программного обеспечения. Спрос на веб-разработчиков находится на рекордно высоком уровне и только растет. В Интернете есть как бесплатные, так и платные учебные пособия, которые научат вас навыкам устроиться на работу в качестве разработчика — степень CS не требуется 🤓.
Сквозной курс для овладения навыками собеседования по кодированию и получения вашей следующей работы в качестве инженера-программиста.
В этой статье подробно описаны необходимые навыки и соответствующие руководства для их эффективного изучения. Иллюстрированное руководство предоставлено Камраном Ахмедом, и его можно найти на roadmaps.sh или в репозитории GitHub — Камран работает превосходно, поэтому обязательно отметьте репо и подпишитесь на его информационный бюллетень, чтобы поддержать его усилия. Не пугайтесь карты. Может показаться, что это много, но я разобью его, чтобы вы могли изучить каждую часть шаг за шагом.
Эта статья будет разделена на следующие разделы:
- Необходимое обучение для любого пути : Концепции программирования, которые необходимо знать каждому разработчику.
- Введение в программирование : С чего начать, если вы новичок в программировании.
- Frontend Development : Узнайте, как создавать пользовательские интерфейсы (UI).
- Backend Development : Узнайте, как создавать API и писать серверный код.
- DevOps Engineering : Узнайте, как управлять инфраструктурой, развертыванием и системами.
- JavaScript и углубленное программирование : Изучите JS сверху вниз.
- Книги по разработке программного обеспечения : Эти книги, которые я считаю, в целом полезны для улучшения моего общего понимания программирования и положительно влияют на работу.(Полный список можно найти здесь)
- Советы по работе и подведение итогов : Несколько заключительных быстрых советов о том, как искать работу и продолжать свой рост в качестве разработчика.
Это все продукты, которые я лично рекомендую. По некоторым из них я получаю компенсацию, если вы воспользуетесь ссылками в статье. Если вы найдете то, что вам нравится, мы будем благодарны за вашу поддержку.
Мы начнем с навыков, которые необходимо освоить каждому разработчику, и они будут использоваться во всех направлениях — Frontend, Backend или DevOps.
Чтобы быть эффективным разработчиком, вы должны хорошо владеть командной строкой, знать, как управлять версиями вашего кода с помощью Git, и понимать основы работы в Интернете.
Командная строка
Командная строка — это то, как вы запускаете свой код. Вы должны уметь перемещаться и выполнять необходимые команды. Чем лучше вы работаете в командной строке, тем эффективнее вы будете как разработчик.
Выберите текстовый редактор
VS Code — лучший выбор для веб-разработчиков, что делает его отличным местом для начала — лично я использую его.Это бесплатный проект с открытым исходным кодом и множеством плагинов, которые сделают вашу работу более продуктивной. Однако есть много отличных вариантов, таких как Atom, WebStorm или Vim (для хардкорных).
Текстовый редактор — это место, где вы будете писать весь свой код, а терминал — это место, где вы его выполняете. Как разработчик, вы здесь живете. Уделите время тому, чтобы выбрать подходящий редактор, настроить плагины и изучить горячие клавиши. Правильный рабочий процесс может значительно повысить вашу производительность.
Git и контроль версий
Git — это инструмент, используемый для сохранения кода и создания различных версий, позволяющий вам сотрудничать с другими разработчиками.Лучшее место для хранения кода и совместной работы над ПО с открытым исходным кодом — это GitHub.
Основы Интернета
Прежде чем вы углубитесь в какой-либо из путей, вы должны иметь прочную основу в программировании. Новым разработчикам я настоятельно рекомендую изучить JavaScript в качестве первого языка. JS можно использовать как для внешних, так и для серверных разработчиков, что означает, что вы можете стать разработчиком полного цикла, имея возможность сосредоточиться на освоении только одного языка. Преимущества JavaScript:
- JavaScript — относительно простой язык для изучения
- JavaScript требуется для создания веб-приложений, поскольку это язык программирования, который работает в браузере.
- JavaScript может использоваться как во внешнем, так и в серверном интерфейсе, позволяет писать полнофункциональные приложения на одном языке.
- Есть масса заданий для разработчиков JavaScript.
. Если вы знаете, что хотите работать либо только с данными, либо исключительно на бэкэнде, изучение Python — другой вариант это хорошо для новичков.
Существует множество высококачественных бесплатных опций для начала кодирования. freeCodeCamp и Codecademy — отличный выбор, они отлично подходят для создания вашей основы.
После того, как вы освоите основы, следующим отличным шагом будет бесплатный курс JavaScript30 или премиальный курс BeginnerJavaScript. Web Bos учит вас основным концепциям JavaScript, создавая реальные проекты. Вы должны стараться делать реальные проекты как можно быстрее. Проекты — лучший способ получить навыки для работы и позволят вам составить портфолио, когда вы начнете собеседование.
Если вы хотите ускорить процесс, это отличные курсы премиум-класса, которые можно начать с новичка в JS и быстро продвигаться.
Современный JavaScript с самого начала
The Modern JavaScript Bootcamp (2020)
Advanced Javascript
Если вы ищете вариант подписки с курсами, которые проведут вас от новичка до профессионала, отличный вариант это Pluralsight. Вы должны подписаться на подписку (предлагается бесплатная пробная версия), но у них есть отличный контент почти по всему.
Frontend-разработка — это то, как мы создаем пользовательские интерфейсы для Интернета. Вы должны иметь прочную основу в JavaScript, а также понимать, как работают HTML / CSS.
Популярные клиентские библиотеки — React, Angular и Vue — все написаны на JavaScript. Тщательное знание ванильного JavaScript необходимо для повышения уровня и наличия необходимых навыков для создания сложных приложений. Если у вас есть прочный фундамент в JavaScript, вам следует изучить HTML и CSS. Несмотря на то, что пользовательский интерфейс написан на JS, он все равно генерирует HTML и стилизован с помощью CSS.
Обратитесь к ресурсам в разделе «Введение в программирование», если вам нужно больше работать с JavaScript.
The Complete 2020 Web Development Bootcamp
Самый полный курс по веб-разработке. Начните с HTML и CSS, изучите JavaScript и то, как он взаимодействует с DOM, и в конечном итоге создайте полнофункциональное веб-приложение.
Учебный курс для веб-разработчиков
HTML и CSS
HTML и CSS обычно изучаются вместе.HTML — это скелет страницы, которая дает структуру, а CSS — язык, который придает ей стиль.
HTML и CSS для абсолютных новичков
Создание адаптивных веб-сайтов реального мира с помощью HTML5 и CSS3
CSS: полное руководство (расширенный CSS)
Библиотеки пользовательского интерфейса (React, Vue, Angular)
Современные Разработка пользовательского интерфейса тяготела к компонентной модели с тремя библиотеками в качестве основных, используемых профессиональными интерфейсными инженерами — React, Vue и Angular.Вам лучше знать , одну из этих библиотек , а не пытаться изучить все 3. Затем на работе вы сможете подобрать что-то другое, если компания использует фреймворк, который вы не изучили. React — самый популярный, но и Vue, и Angular быстро внедряются.
React
Официальное введение в React
React — Полное руководство (включая хуки, маршрутизатор React, Redux)
Modern React с Redux
React для начинающих Advanced + GraphQL
Vue
Официальное введение в Vue
Vue JS 2 — Полное руководство (вкл.Vue Router и Vuex)
Курс для разработчиков Ultimate Vue JS 2
Vue JS Essentials с Vuex и Vue Router
Angular
Angular 8 — Полное руководство
От новичка до продвинутого уровня
Бэкэнд — это место, где вы общаетесь с базой данных, обрабатываете бизнес-логику и отправляете необходимые данные во внешний интерфейс.
Ваш бэкэнд / сервер может быть написан на любом языке.Я рекомендую начать с Node / JavaScript, поскольку его относительно легко изучить, но при этом он невероятно мощный. Кроме того, вам будет проще переходить между интерфейсом и сервером, поскольку вы будете использовать один и тот же язык для каждого. Я также подробно расскажу о других возможных языках для изучения серверной разработки — Python, Go, Ruby on Rails.
Работа с базой данных — это основная задача бэкэнд-инженера, и я также опишу учебные пособия по изучению SQL, NoSQL и GraphQL. Хотя NoSQL стал более популярным, SQL по-прежнему является наиболее часто используемым типом баз данных, и его необходимо изучать.
Node.js
Узел — это то, как мы выполняем JavaScript вне браузера, который можно использовать для создания API-интерфейсов на бэкэнде / сервере.
Полный курс разработчика Node.js (3-е издание)
NodeJS — Полное руководство (включая MVC, REST API, GraphQL)
Learn Node
Базы данных
База данных является постоянной хранилище данных вашего приложения. Обычно серверная часть делает запрос к базе данных во время вызова API.Есть 2 распространенных типа баз данных — SQL и NoSQL.
PostgreSQL / MySQL
Это две основные реализации SQL, которые, вероятно, будут использоваться в большинстве компаний.
GraphQL
GraphQL сам по себе не база данных, а язык запросов поверх баз данных. Многие люди верят, что это произведет революцию в разработке приложений и полностью изменит способ создания API. Он быстро получает распространение и используется технологическими гигантами и ведущими стартапами.
В качестве бонуса попробуйте Хасуру.Он позволяет создавать GraphQL с помощью веб-интерфейса и автоматически создает для вас базу данных Postgres.
MongoDB
Mongo — самая популярная база данных NoSQL, используемая с Node. Он хранит данные в документах, которые представляют собой пары , ключ /, значение , которые легко сопоставляются с объектами JSON и JavaScript. Это
Python
Python прост для новичков, но также широко используется техническими гигантами и стартапами для бэкендов, обработки данных и создания сценариев.
Complete Python Bootcamp: переходите от нуля к герою в Python 3
Python и Django Full Stack Web Developer Bootcamp
Go (Golang)
Go является относительно новым, но быстро внедряется.Это язык со статической типизацией, но он также невероятно удобен для разработчиков. Это делает его идеальным для использования в строительстве.
Ruby on Rails
Ruby on Rails в течение многих лет был языком стартапов. Его простота использования и язык, основанный на условных обозначениях, позволили легко создавать продукты.
DevOps управляет инфраструктурой компании. Они настраивают процессы для развертывания ваших веб-приложений и управления трафиком на сайт. Инженеры DevOps сосредотачиваются на том, чтобы позволить другим командам как можно быстрее вводить код в производство, и следить за тем, чтобы серверы всегда были в рабочем состоянии, и отправлять контент конечному пользователю как можно быстрее.
Область DevOps очень широка, и выбор, который они делают, влияет на каждую команду инженеров. Вот некоторые важные темы, которые следует изучить как DevOps-инженеру:
- Linux : Linux используется на более чем 67% серверов, и, скорее всего, вы бы использовали его как DevOps-инженера. Это необходимо досконально понять.
- Безопасность : Убедитесь, что все ваше облако защищено и зашифровано. Также настройте API так, чтобы весь контент обслуживался через HTTPS и не был подвержен распространенным атакам.
- Командная строка / Терминалы : Мы представили командную строку в первом разделе, но она еще более важна для инженера DevOps. Вы должны полностью понимать, как это работает, и команды Linux, а также быть готовым к подключению по SSH к удаленным серверам. Вы также будете писать сценарии и автоматизировать программы для всей компании.